Keywords: Reinforcement Learning, Human-In-The-Loop, Music Generation, HITL RL, Algorithmic Music, Audio Machine Learning, Human Feedback, RLHF, Human-Agent Teaming
Why This Paper?
이번에 연구실에 들어오면서 여러가지 논문을 읽게 되었다. 나는 강화학습과 음악 생성 AI에 관심이 있었기에 관련된 것을 찾아보다가 제일 먼저 발견한 논문이 바로 이것이다.
Introduction
기존의 음악 생성 연구는 데이터 의존성을 피하기 어려워 저작권 문제나 오픈소스 음악의 영향을 받는 경우가 많았다. 따라서 이 논문에서는 Human-In-The-Loop Reinforcement Learning을 활용하여 데이터 의존성을 제거하고, 사용자 취향에 맞춘 음악을 생성하는 AI를 제안하였다.
Background
논문에서는 Reinforcement Learning(강호학습)과 Human-In-The-Loop(HITL) 알고리즘을 음악 생성에 사용한다. 그렇기에 이 두가지에 대한 간단한 배경지식을 먼저 설명한다.
A. Reinforcement Learning
RL을 통한 음악 생성은 독창적인 음악을 생성할 수 있다는 점에서 새로운 도구로 주목을 받았다. Hong et al.의 연구에서는 deep reinforcement learning을 이용하여 MIDI 음악 생성을 하였으며 Jin et al.의 연구에서는 메타버스 콘서트의 framework를 생성하며 RL을 사용하였다. Reese et al.은 기하학적 네트워크와 RL 모델을 활용하여 화성 음악 생성을 연구하였으며, 코드 진행과 음악 스케일 데이터의 중요성을 강조하였다. Chen et al.은 기존 Guzheng 음악 데이터를 기반으로 RL 기법을 사용해 Guzheng 음악의 독특한 특징을 포착한 자동 작곡 방법을 제안하였다.
B. Human-In-The-Loop Algorithms
HITL 알고리즘은 인간의 입력과 피드백을 결합하여 의사 결정을 하는 시스템을 의미한다. 음악 생성의 관점에서 HITL 알고리즘은 유저의 선호도와 창의적인 통찰력을 결합하는 것을 목적으로 한다.
HITL 알고리즘은 음악 생성에 널리 활용되었으며, Bryden은 사용자가 직접 진화를 유도하는 HITL 진화 알고리즘을 제안하였고, Pei는 인터랙티브 진화 계산을 활용한 사운드 및 음악 작곡에 대한 설문 연구를 통해 HITL의 역할을 강조하였다. 또한, Tavakoli의 HARMONY 프로젝트는 복잡한 작업에서 인간 중심 데이터 수집의 효과를 입증하였다. 이러한 연구들은 HITL이 다양한 분야에서 세밀하고 강력한 알고리즘적 솔루션을 제공할 수 있는 유용한 방법론임을 보여준다.
C. Human-In-The-Loop Reinforcement Learning
기존의 RL과 비교하면 HITL RL은 사용자의 참여를 유도하고, 사용자의 전문 지식을 활용하여 알고리즘 결과를 향상시킨다. HITL RL은 다양한 응용 분야에서 높은 적응성과 효율성을 보여주었다. Alamdari는 개인 맞춤형 보청기 압축에서 사용자 선호도를 반영하는 HITL RL의 가능성을 제시하였고, Luo는 연속적 행동 공간에서 복잡한 환경 학습을 강화할 잠재력을 강조하였다. Reese와 Wu의 연구는 인간 지능과 기계 학습의 상호작용을 통해 HITL RL의 다재다능함을 보여주었다. 이러한 연구들은 특히 주관적 판단이 중요한 창의적 영역에서 적응성과 효율성을 증대시키는 인간-에이전트 협업의 중요성을 부각하지만 아직 음악 생성에서 HITL RL의 적용은 아직 연구되지 않은 미개척 분야로 남아 있다.
D. Knowledge Gaps
HITL 알고리즘과 RL은 개별적으로 창의적인 어플리케이션에 영향을 미치고 있다. 그러나 두 가지를 결합하는 방법은 기존의 음악 생성에서 RL 의존성을 극복할 수 있는 잠재력을 가지고 있다. 기존의 강화학습을 이용한 음악 생성에서는 데이터의 중요성을 강조하지만 HITL 알고리즘을 이용할 경우 데이터와 관련 없이 창의적인 음악을 생성할 수 있을 것이다.
Method
A. Solution Formulation and Algorithm
강화학습 알고리즘으로는 Q-Learning을 사용하였다. Q-Learning은 Markov Decision Process(MDP)와 같은 의사 결정 문제에서 사용한다. MDP는 states(상태), actions(행동), rewards(보상) 등으로 이루어져 있다.
여기에서는 "트랙 배열" 이라는 컨셉을 사용한다. 트랙 배열은 멜로디와 타악기 요소로 구성이 되어 있으며, 사용자가 정의한 파라미터에 따라 초기화 된다. 이러한 입력 값을 바탕으로 생성되며 멜로디의 음의 높이는 무작위로 선택된다. 또한 타악기 요소도 무작위로 생성된다.
하나의 트랙 배열에는 [멜로디 배열, 타악기 배열]로 구성이 되어 있고 멜로디 배열은 [(음1, 지속시간1), (음2, 지속시간2)...]으로 구성되며 타악기 배열은 [타익기1, 타악기2, ...]으로 구성된다.
이러한 구조를 이용하여 Q-Learning 알고리즘은 트랙 배열에 대한 학습을 진행한다. 사용자가 음악을 듣고 1~10의 보상을 주면 알고리즘은 보상을 극대화하기 위해 행동(action)을 조정한다. action은 총 6가지로 이루어져 있으며 피치를 1 올리거나 내리기, 지속시간 0.25 늘리고 줄이기, 타악기 변경하기, 삭제하기가 가능하다. Q 함수는 아래의 식처럼 업데이트한다.
Q(s, a) ← Q(s, a) +α [R(s, a) + γ * max(Q(s', a')) - Q(s, a)]
B. Exploration Strategies
입실론-그리디(Epsilon-Greedy) 전략은 탐색(exploration)과 활용(exploitation) 간의 균형을 맞춰준다. 여기서 exploration은 새로운 가능성을 실험하는 것이고 exploitation은 기존의 알고 있는 경험에서 최적이라고 판단되는 것을 행동한다. RL에서 이 두 가지의 조화는 굉장히 중요한데 입실론 그리디의 경우 만약 ε의 확률이라면 exploration을 진행하고 1 - ε의 확률이라면 exploitation을 진행하여 Q의 값이 제일 높은 행동을 선택한다.
C. Training Process
훈련 과정은 최소 10개의 에피소드로 구성되며 각 에피소드의 트랙 배열은 유저의 입력과 음악 이론의 지식을 바탕으로 구성된다. 각 단계마다 트랙 배열의 상태 s는 RL을 이용하여 진행되며 ε의 경우 0.5의 값을 사용한다. 매 에피소드마다 트랙 배열을 통해 음악이 생성되고 사용자는 그 음악을 듣고 평가를 진행한다. 이 평가 점수가 보상으로 사용되어 Q의 값들을 업데이트한다. 사용자들은 10개의 에피소드를 진행한 뒤 추가로 훈련을 진행할 수 있는 옵션이 제공된다. 모델에 시간을 투자할수록 Q 값을 정교하게 조정하여 개별적인 취향에 맞춘 작곡을 생성하는데 더 적합해질 수 있다.
에이전트들에게는 외부 데이터나 기존 음악이 전혀 제공되지 않기 때문에 창의적 자율성이 보장받는다.
D. Evaluation Metrics
사용자들에게 생성된 음악에 대해 점수를 제공하는 것을 부탁했다. 각 점수는 1-5점으로 음악성, 독창성, 일관성의 3가지 부분에서 측정하도록 부탁했다.
음악성(Musicality) : 얼마나 음악적으로 듣기 좋고 일관성 있는지 평가
독창성(Novelty) : 기존 음악과 비교하여 생성된 음악이 얼마나 독창적이고 참신한지 평가
일관성(Coherence) : 생성된 음악의 구조적 일관성과 요소 간의 통합을 평가
Results
평가에는 총 13명이 참여했다. 음악 이론에 대한 전문 지식과 3명과 음악을 작곡한 경험이 있는 3명을 포함했다.
A. Model Training Evaluation
각 에피소드에서 사용자 평가 점수의 추이를 분석했다. 아래 그림을 보면 훈련 에피소드의 품질이 개선되는 모습이 보인다. 이는 알고리즘이 지속적인 훈련을 통해 학습하고 더 나은 음악을 생성할 수 있음을 나타낸다.

그리고 입실론을 0.5로 사용하여 RL 에이전트가 균형 잡힌 방식을 사용했다. 아래 그림은 훈련 과정 동안 exploration과 exploitation의 균형을 보여준다.

B. User Interaction and Feedback
HITL 과정에서 사용자의 참여는 사용성과 효과성을 평가하는데 중요한 역할을 했다. 사용자들은 음악 생성을 평가한 후 피드백을 제공했다. 아래 그림은 음악 이론에 대한 이해도와 작곡 경험을 통해 참가자들의 음악적 전문성을 보여준다.


위에서 말했던 것처럼 참가자들은 3가지의 관점에서 1-5점의 점수를 측정했다. 대부분의 작품이 음악성과 참신성에서 좋은 평가를 받았다. 그러나 일관성 평가는 더 넓은 분포를 보여 잠재적인 개선이 필요하다. 아래 그림은 참가자들의 3가지 관점에서의 점수를 그래프로 나타낸 것이다.
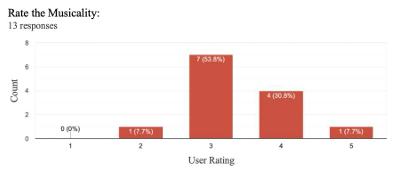


그리고 참가자들에게 피드백을 받았는데 일반 사용자와 전문 사용자로 나누어서 진행했다.
일반 사용자의 경우, 데이터 없이 모델이 학습되었다는 점과 이론이 없는 사용자도 작곡을 할 수 있다는 점을 고평가했다.
전문 사용자의 경우, 초안을 빠르게 생성하는 것에는 유용하지만 화성 진행(chord progressions)과 타악기 레이어링(percussion layering)에서는 세부적인 조정이 필요하다고 지적했다.
Conclusion
이 논문에서는 HITL RL과 음악 이론의 원칙을 결합한 새로운 알고리즘적 음악 생성 방식을 제안했다. 강화학습과 사용자 상호작용을 통해 독창적이고 개인화된 음악 작곡이 가능함을 입증했다.
그러나 여전히 화성 진행의 세부 조정이나 표현력과 같은 과제가 남아있다. 그래도 이 모델은 음악 작곡에서 실험과 창의성을 촉진하는 데 유용하다.
향후 연구에서는 다른 강화학습 알고리즘과의 비교 연구, 입실론-그리디를 제외한 다른 탐색 전략의 효과를 평가해볼 필요가 있으며 음악성, 독창성, 일관성과 같은 지표를 통합한 복합 보상 함수를 탐색할 필요가 있다.
느낀점
여러가지 연구 주제를 생각했었는데 그중에 처음 생각났던게 딱 이런 주제였다. 사람의 생각은 대부분 비슷하기 때문에 어떤 주제가 생각나도 웬만하면 다 있을거라고 하던데 진짜 그랬다. 원래 생각을 하던 주제여서 그런지 좀 더 흥미롭게 읽을 수 있던 것 같다.
https://ieeexplore.ieee.org/document/10386567
Music Generation using Human-In-The-Loop Reinforcement Learning
This paper presents an approach that combines Human-In-The-Loop Reinforcement Learning (HITL RL) with principles derived from music theory to facilitate real-time generation of musical compositions. HITL RL, previously employed in diverse applications such
ieeexplore.ieee.org