AGI 수업에서 2주차 내용에 관련된 Chollet의 논문이다. 수업을 듣기 전에 미리 읽어보고 내용을 정리해보고자 한다.
Context and history
Need for an actionable definition and measure of intelligence
AI 연구는 인간과 유사한 지능을 가진 기계를 개발하는 것을 목표로 하지만, 현재까지 AI는 특정 작업에 특화된 시스템을 만드는 데에만 성공했다. AI 시스템은 여전히 취약하고, 데이터에 의존하며, 새로운 상황에 대한 적응력이 부족하다. 연구의 진전이 미흡한 이유 중 하나는 명확한 목표와 평가 기준이 부족하기 때문이다.
현재까지 AI 지능에 대한 객관적이고 실행 가능한 정의나 평가 기준이 제대로 확립되지 않았으며, 기존의 튜링 테스트 같은 방법은 지능을 명확히 측정하는 데에 부적절하다. 또한, AI 연구 커뮤니티는 지능에 대한 기존 연구 결과를 충분히 반영하지 않고 있으며, AI가 인간을 특정 게임에서 이기는 것과 같은 편향된 연구 경향을 보이고 있다.
본 논문은 이러한 문제를 지적하고, 발달 인지심리학의 최신 연구를 활용하여 인간과 유사한 일반 지능을 정의하고 평가하는 체계를 제안하는 것을 목표로 한다.
Defining intelligence: two divergent visions
지능에 대한 단일한 정의는 아직 존재하지 않으며 연구자들마다 다르게 정의해왔다. 그래도 공통된 말을 요약하면 "다양한 환경에서 목표를 달성하는 능력" 이라고 할 수 있는데 여기에는 특정 작업 수행 능력과 일반성과 적응성의 2가지 특성을 강조한다.
이러한 개념은 Catell의 유동성 지능과 결정성 지능 이론과 연결되며, 인간 지능에 대한 두 가지 상반된 관점과도 관련이 있다. 이 논문의 핵심 목표 중 하나는 암묵적으로 따르던 이 2가지 개념을 명확하게 규명하고 비판적으로 평가하는 것이다.
지능 : 개별적인 작업 수행 능력(Intelligence as a collection of task-specific skills) 초기 AI 연구는 정적인 프로그램과 논리 연산으로 지능을 구현할 수 있다는 관점에서 시작하여 지능을 개별적인 작업 수행 능력의 집합으로 보았다. 이런 접근 덕분에 AI 시스템은 특정 작업을 잘 수행할 수 있게 되었지만 인간처럼 일반적이고 유연한 지능을 갖추지는 못하는 상황이 발생했다. AI 연구에서는 지능의 본질이 무엇인지에 대한 논의가 부족한 상태에서 연구가 지속되고 있다.
지능 : 일반성(Intelligence as a general learning ability) AI를 위처럼 특정 작업 수행능력으로 정의한 Minsky에 반대로 McCarthy는 AI가 사전 준비되지 않은 상태로 새로운 작업을 수행할 수 있어야 한다고 주장했다. 머신러닝이 주요 방법이 되면서 연구자들은 머신러닝을 AI 연구의 주요 패러다임으로 사용한다. 하지만 현재 AI 연구자들은 마음을 무작위로 초기화된 신경망으로 바라보는 오류를 범하고 있으며, 이는 과거 AI 연구자들이 마음을 정적인 컴퓨터 프로그램으로 바라보았던 오류와 유사하다.
결과적으로 지능을 특수 목적 프로그램들의 집합으로만 설명하는 것도, 완전히 백지 상태로만 설명하는 것도 충분하지 않으며, 보다 정교한 이론이 필요하다.
AI evaluation: from measuring skills to measuring broad abilities
AI 지능 평가 방법은 특정 지능 개념에 따라 다양하게 발전해왔다.
Skill-based, narrow AI evaluation
AI 연구는 특정 작업 수행 능력을 중심으로 평가되어 왔으며, 역사적으로 성공한 접근 방식으로는 벤치마크, 경쟁 평가, 화이트박스 분석, 인간 심사가 있다.
- 인간 심사(Human Review) : 인간 심사위원이 AI 시스템의 입력-출력 응답을 관찰하고 점수를 매김
- 화이트박스 분석(White-box Analysis) : AI 시스템의 구현을 직접 분석하여 입력-출력 응답을 평가
- 경쟁 평가(Peer Confrontation) : AI가 다른 AI 또는 인간과 경쟁하는 방식으로 평가(PvP 게임에서 선호)
- 벤치마크 평가(Benchmarks) : 테스트 셋을 이용하여 AI 시스템의 출력을 평가
이 중에서 벤치마크 기반 평가는 연구 발전을 촉진했지만 특정 작업에 최적화된 AI는 일반적인 지능을 가지지 못한다. 그렇기에 AI의 목표가 특정 작업이 아니라 '일반적인 학습 능력'이라면 새로운 평가 방식이 필요하다.
The spectrum of generalization: robustness, flexibility, generality
일반화란 AI 시스템이 이전에 접하지 않은 상황(작업)을 다룰 수 있는 능력으로 정의할 수 있다. 그러나 이전에 접하지 않은 상황이라는 개념이 모호할 수 있으므로 일반화의 두 가지 유형을 구별해야 한다.
- 시스템 중심 일반화 : 시스템 자체가 새로운 데이터에서 얼마나 잘 작동하는지 평가
- 개발자 인식 일반화 : 시스템뿐만 아니라 개발자도 예측하지 못한 상황에서의 성능을 평가
정보 처리 시스템에서 일반화를 보다 명확하게 구분하기 위해 질적(qualitative) 수준에 따라 일반화의 다양한 단계를 정의하는 것이 유용하다.
- 일반화 없음(Absence of Generalization) : 완전 탐색, 정렬 알고리즘과 같이 사전에 모든 경우를 알고 있는 경우
- 국소적 일반화(Local Generalization) : 머신러닝이 주로 다루는 영역, 기존 분포 내에서 새로운 데이터 처리 가능
- 광범위한 일반화(Broad Generalization) : AI가 새로운 환경에서도 적용될 수 있는 능력
- 극단적 일반화(Extreme Generalization) : 완전히 새로운 작업을 수행할 수 있는 능력(현재는 인간과 일부 생물학적 지능만 가능)
현재 AI 연구의 목표는 광범위한 일반화(Broad Generalization)로 이동 중이며, 극단적 일반화는 인간만이 수행할 수 있는 능력으로 남아 있다.
위의 목록에 이론적으로 보편성이라는 개념을 추가할 수 있다. 보편성은 일반성을 인간이 수행할 수 있는 작업 범위를 넘어서 우주 내에서 수행할 수 있는 모든 작업까지 확장하는 개념이지만 AI 연구의 합리적인 목표는 될 수 없다고 판단된다.
AI 연구의 역사는 일반화의 스펙트럼을 점진적으로 확장해온 과정이라고 볼 수 있다.
- 초기 AI(Symbolic AI) : 일반화 없음
- 머신러닝의 발전 : 국소적 일반화(Local Generalization) 가능
- 현재 연구 단계 : 광범위한 일반화(Broad Generalization) 목표
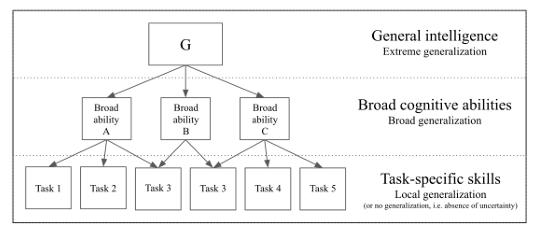
AI의 일반화 개념은 인간의 인지 구조 모델(CKHC, g-VPR, 그림 1 참고)과 유사한 형태를 보인다. 극단적 일반화는 g factor, 광범위한 일반화는 broad abilities, 국소적 일반화 및 일반화 없음은 task-specific skills.
앞으로 사용하는 용어들은 아래와 같이 뜻을 정의하여 사용한다.
- 광범위한 능력 = 광범위한 일반화 또는 극단적 일반화를 가능하게 하는 인지 능력
- 일반화 = 국소적 일반화부터 극단적 일반화까지 포함하는 개념
- 지능 또는 일반 지능 = 극단적 일반화(Extreme Generalization)와 동일한 의미로 사용됨
Measuring broad abilities and general intelligence: the psychometrics perspective
심리측정학에서 지능 검사는 특정 작업이 아닌 광범위한 인지 능력(신뢰성, 타당성, 표준화, 편향 최소화)을 평가하는 방식으로 발전해 왔다. AI 평가에서도 다중 작업 벤치마크가 등장했지만 사전에 알려진 작업을 연습할 수 있기 때문에 기술을 평가하는 한계를 벗어나지 못한다.
이것을 벗어나기 위해 실험적인 AI 평가 방법도 제안되었지만 대부분 실제로 구현되지 않았고, 대신 최근에 실용적인 테스트가 등장했다.
- Animal-AI Olympics : AI가 보지 못한 새로운 작업을 수행할 수 있는지를 평가, 학습 능력과 계획 수립 능력을 테스트
- GVGAI Competition : 멀티 게임 환경에서 AI가 새로운 게임을 해결할 수 있는지 평가
위의 두 테스트는 심리측정학의 지능 평가 원리와 유사한 접근을 시도하고 있다.
Integrating AI evaluation and psychometrics
과거에는 인간을 위한 심리측정 테스트를 그대로 AI에 적용하려는 시도가 있었으나, 개발자들이 미리 해답을 알고 문제를 하드 코딩하는 방식으로 AI 시스템에 쉽게 주입할 수 있기 때문에 의미 있는 지능 평가로 볼 수 없다.
보다 나은 대안은 심리측정학의 평가 원칙을 바탕으로 AI 전용 평가 방법을 개발하는 것이다. 이 방법에서의 중요한 질문은 아래와 같다.
- 이 테스트는 어떤 가정을 기반으로 설계되었는가?
- 테스트가 정확히 어떤 광범위한 능력들을 예측하고 평가하는가?
- 테스트 결과가 실제로 해당 능력을 얼마나 잘 예측하는가? (예측 타당성)
이를 위해 AI와 인간 모두에게 공정한 테스트를 구성하여 사전에 알려지지 않은 작업들에 대한 일반화 능력을 평가해야 한다. 주의할 점은 인간 인지 능력의 이론은 참고 자료로써만 활용되어야 하며 AI 시스템의 특성을 고려하여 능력 평가를 위한 새로운 테스트 디자인이 요구된다.
Current trends in broad AI evaluation
현재 AI 평가 방식은 아래와 같은 한계점 및 문제점이 존재한다.
- 로버스트성 평가 부족 : 현재 AI 시스템은 강건성(robustness)이 매우 취약한 경우가 많음
- 지나지체 기술 중심 평가 방식 : 여러 프로젝트가 보드게임 및 비디오 게임 같은 task-specific 기술 평가를 목표로 한다
- 다중 작업(multi-task) 벤치마크의 한계 : 여러 벤치마크는 평가할 작업이 미리 개발자에게 알려져 있어 실제 일반화 평가로 보기 어렵다
- 능력 중심 평가 방식의 미흡한 개발 : AI 평가에서 능력 지향적이고 일반 목적의 평가 방식은 여전히 초기 단계
그렇기에 심리측정학(Psychometrics)에서 사용하는 능력 지향적 평가 방식이 AI 평가에 중요하게 도입될 필요가 있다. AI 평가에 심리측정학의 접근 방식을 도입하여 광범위한 능력(broad abilities)과 극단적 일반화(extreme generalization)를 정확히 평가할 수 있는 체계를 구축해야 한다.
A new perspective
Critical assessment
Measuring the right thing: evaluating skill alone does not move us forward
특정한 단일 작업에서 인간을 초월하는 성능을 내는 AI는 그 작업 외에 일반화되지 못하므로 일반적인 지능 연구로 이어지지 않는다. 과거에는 인간을 능가하는 체스 AI 딥블루가 나왔지만 사람들은 이런 작업이 인간의 인지나 일반적 능력의 이해로 이어지지 않는다는 것을 깨달았다.
단일 작업을 잘 하는 것이 아니라 새로운 문제를 배우고 적응하는 일반화 능력이 진정한 지능의 특징이다. 무한한 사전지식(prior)이나 데이터로 특정 작업의 성능만 높이는 방식은 진정한 일반화를 보여주지 못한다.
인간 및 동물과 같은 진정한 지능적 시스템은 사전지식과 경험을 모두 사용하지만일반화 능력은 이러한 요소들과 독립적이다. 따라서 진정한 AI 평가를 위해서는 사전지식, 경험, 작업의 일반화 난이도를 명확히 통제한 평가가 필수적이다.
The meaning of generality: grounding the g factor
인간의 인지 능력은 다양한 능력들이 위계적으로 구성된 구조로 되어 있으며(그림 1 참고) 꼭대기에는 하나의 일반 지능 요인(g factor)이 존재한다. 그러나 일반 지능이란 개념이 과연 절대적인 보편성을 가지는지 단지 인간이라는 한정된 범위 내에서 광범위한 일반성을 가지는지에 대한 의문이 있다.
No Free Lunch 우주 전체의 모든 가능한 문제를 고려할 때 인간 지능도 다른 알고리즘과 평균적으로 동등하다는 이론이다. 즉, 인간의 일반 지능도 보편적이지 않고 우주에 존재하는 모든 작업에 일반화가 불가능하다는 것이다. 결국 인간의 지능은 인간에게 의미 있는 작업에만 특화되어 있으며 보편적 지능이라고 보기는 힘들다.
인간은 역사적으로 자신과 다른 존재나 시스템이 지능적이라고 쉽게 인정하지 않았으며, 오직 인간과 비슷한 친숙한 행동을 보일 때만 지능적이라고 판단하는 경향이 있다. 이러한 점을 고려할 때, AI 연구는 절대적인 보편성을 가진 보편적 지능(universal intelligence)을 추구하기보다는, 인간의 인지를 기준으로 한 특정 범위의 일반성을 목표로 하는 것이 더 현실적이다.
인간의 신체능력을 측정할 때 나이, 근육량 같은 단일 요인으로는 설명되지 않으며 여러 상호의존적 요인들로 구성되어 있다. 그러나 인간의 신체 능력이 절대적 의미에서 보편적이라고는 볼 수 없다. 인간은 우주 대부분 환경에서 적응할 수 없기 때문이다.
인지 능력(cognitive abilities)도 마찬가지이다. 인간은 피아노 연주, 선형대수, 수영 등 여러가지 적응력을 가지고 있지만 장기 기억이나 사전 지식에 맞지 않는 문제에서는 뛰어난 성능을 보이지 못한다. 그렇기에 인간의 인지 능력을 절대적 보편성과 혼동해서는 안된다.
결론적으로 AI 분야에서의 일반지능의 목표는 인간이 가진 제한적 일반성을 기준으로 삼아야 하며, 절대적 보편성을 지향하는 것은 적합하지 않다.
인간의 인지 능력에는 분명한 차원적 편향(dimensional bias)이 존재한다. 예를 들어 인간은 2차원 과제에 특화되어 있지만 3차원 이상의 과제에서는 성능이 급격히 떨어진다. 이는 인간 지능이 진화 과정에서 특정 환경과 문제에 맞춰 형성되었기 때문이다.
여기서 중요한 것은 일반 지능이 시스템이 가지거나/가지지 않거나하는 이분법적 속성이 아니라는 것이다. 일반 지능은 작업의 일반화 난이도, 적용 범위, 일반화 능력 등을 기준으로 하는 연속적인 스펙트럼이다.
적용 범위(scope)의 가치는 주관적이며, 인간과 겹치는 범위 내의 지능만이 인간에게 의미가 있다.따라서 모든 가능한 문제를 다루는 보편적 지능을 목표로 하는 것은 타당하지 않으며, 인간의 지능을 기준으로 평가하는 것이 현실적이다.즉, AI 연구의 목표는 인간과 유사한 범위에서의 일반성을 정의하고 측정하는 것이어야 한다.
Separating the innate from the acquired: insights from developmental psychology
기존의 정신 본질에 대한 두 가지 상반된 관점(특수 목적에 최적화된 구조 vs 완전한 백지 상태)은 모두 잘못된 것이다. 인간의 인지 기능은 특정 방향으로 진화적 영향을 받아 전문화되어 있어 다양한 기술을 효과적으로 습득이 가능하다.
학습을 위해서는 반드시 특정한 가정을 세워야 하며, 인간의 마음이 가진 이러한 선천적 가정이 인간의 효율적인 학습 능력을 가능하게 한다. 인간의 선천적 인지 가정은 크게 3가지로 구분된다.
- 낮은 수준(Low-level): 감각과 운동의 기본 구조에 관한 것
- 중간 수준(Meta-level): 학습과 추론을 가능하게 하는 일반적 원칙
- 높은 수준(High-level): 세계의 객체와 현상에 관한 직관적 사전 지식
인간과 유사한 인공지능을 평가할 때는 낮은 수준(감각운동)의 선천적 지식은 평가에 적합하지 않고 높은 수준의 지식(인간이 타고난 지식)을 기준으로 삼아야 한다. 인간의 선천적인 지식 기반을 갖추지 못한 시스템은 인간과 비교했을 때 불리할 수밖에 없지만 반대로 너무 많은 사전 지식을 부여하는 경우에는 일반화 능력과 무관한 작업의 성능 향상만 초래하기 때문에 평가를 왜곡할 수 있다.
인간과 유사한 일반 지능을 정확히 평가하려면 인간이 지닌 타고난 지식 가정을 기준으로 삼아야한다. 본 논문에서는 아래의 평가 기준을 제안한다.
- 평가하는 기준은 인간이 가진 타고난 지식 가정과 최대한 근접하게 설정
- 테스트는 평가 대상이 특정 지식 가정을 가진다고 명학하게 가정, 사용하는 선천적 가정은 명확하게 설명되어야 함
- 테스트에서 가정하는 지식은 순수하게 타고난 지식이어야 함, 이미 습득한 학습된 지식(ex. 체스)은 안됨
여기서 핵심적인 질문이 등장한다. "인간이 가지고 있는 선천적인 지식은 정확히 무엇인가?"
이 질문의 답을 제공하는 것이 발달 심리학의 핵심 지식 이론(Core Knowledge)이다.
- 객체성(objectness) 및 기초 물리 : 응집성, 지속성, 접촉의 원리로 객체를 인식
- 행위자성(agentness) 및 목표 지향성 : 목표를 가지고 효율적으로 행동하는 존재로 행위자를 인식
- 자연수 및 기초 산술 능력 : 작은 숫자에 대한 기본적이고 추상적인 이해, 산술 연산 능력
- 기초 기하학 및 위상학 : 공간 내에서의 거리, 방향, 안/밖 관계에 대한 직관적 이해
따라서, 본 논문에서는 인간과 기계가 공정하게 평가받을 수 있도록, 인간과 유사한 일반 지능을 측정하는 테스트는 반드시 위의 네 가지 핵심 지식 체계만을 전제로 해야 하며, 이 선천적 가정 이외의 추가적인 학습된(acquired) 지식을 포함해서는 안 된다고 제안한다.
Defining intelligence: a formal synthesis
Intelligence as skill-acquisition efficiency
지금까지 말한 내용을 요약해서 정의하면 지능이란 특정 작업 범위에 걸쳐 주어진 사전 지식, 경험, 일반화 난이도를 고려하여 기술을 습득하는 효율성을 나타낸다.
이 논문에서는 위와 같은 직관을 바탕으로 지능을 공식적으로 정의하고 평가할 방법을 제안하며, 이것이 광범위하고 일반적인 AI 연구에 유용한 기준이 되는 것을 목표로 한다.
Position of the Problem
작업과 지능 시스템 간 상호작용은 두 가지 요소를 통해 이루어진다
- 스킬 프로그램(skill program) : 지능 시스템에서 생성되는 부분
- 점수 함수(scoring function) : 과제에 포함된 부분
모든 프로그램은 고정된 하나의 범용 튜링 기계(universal Turing machine)에서 동작한다고 가정한다. 그리고 상황 공간(Situation Space)과 반응 공간(Response Space)의 존재를 가정한다. 이 정의는 완전 지도학습, 부분 지도학습, 강화학습을 모두 모델링할 수 있는 프레임워크이다.
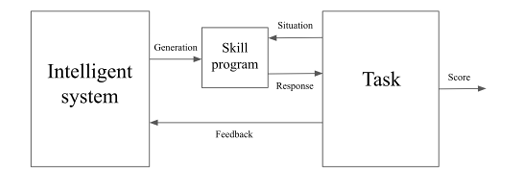
여기서 작업(Task) $T$는 아래 4가지 요소로 구성된다.
- 작업 상태 $TaskState$
- 작업의 상태를 나타내는 이진 문자열(binary string)
- 상황 생성 함수 $SituationGen$ : $TaskState \to Situation$
- 확률적(stochastic)일 수 있다
- $Situation$은 $SituationSpace$에 속한 이진 문자열이다
- 점수 함수 $Scoring$ : $[Situation, Response, TaskState] \to [Score, Feedback]$
- 확률적(stochastic)일 수 있다
- 점수 $Score$ : 스칼라 값이며 특정 상황에 대한 반응의 적합성(appropriateness)를 평가한다
- 피드백 $Feedback$ : 이진 문자열이며 현재 점수에 대한 전체 또는 일부 정보를 포함하거나, 이전 반응들에 대한 점수 정보를 포함할 수 있다
- 자기 갱신 함수 $TaskUpdate$ : $[Response, TaskState] \to TaskState$
- 최근 상황에 대한 반응을 기반으로 작업 상태를 갱신, 확률적일 수 있다
예를 들어 ARC 벤치마크에서 제시된 과제, 체스, 워크래프트3와 같은 게임은 하나의 작업(Task)로 간주할 수 있다. 이때 체스판의 상태, 게임의 프레임 등은 모두 상황(Situation)에 해당한다.
여기서 지능형 시스템$IS$는 아래 3가지 요소로 구성된다.
- 시스템 상태 $ISState$
- 시스템의 상태를 나타내는 이진 문자열(binary string)
- 스킬 프로그램 생성 함수 $SkillProgramGen : ISState \to [SkillProgram, SPState]
- 입력된 상황을 유효한 응답으로 변환
- 자체적인 상태(SPState)를 가지고 있어 여러 상황을 독립적으로 연속하여 처리 가능
- 자기 상태 갱신 함수 $ISUpdate : [Situation, Response, Feedback, ISState] \to ISState$
- 시스템이 최근의 상황 및 피드백을 기반으로 자체 상태를 변화시키는 함수
지능 시스템은 특정 작업을 위한 스킬 프로그램을 생성하며, 생성된 스킬 프로그램은 작업 상황을 받아 이에 대응하는 적절한 반응을 출력한다. 과정은 훈련 단계와 평가 단계로 나뉜다.
- 훈련 단계(아래의 내용을 반복)
- 훈련 상황을 생성
- 지능 시스템(IS)은 현재 상황에 대한 지식 없이 새로운 스킬 프로그램을 생성
- 스킬 프로그램이 현재 상황에 대해 반응을 출력
- 작업의 평가 함수가 반응에 대해 점수를 부여하고 피드백을 생성
- 지능 시스템은 받은 피드백을 통해 내부 상태를 업데이트
- 작업 상태를 최신 상황에 대한 반응을 토대로 업데이트
훈련 단계는 SituationGen 함수가 STOP을 반환하면 종료된다. 이때 최종 스킬 프로그램이 생성된다. 평가 단계는 훈련 단계와 비슷하지만 하나의 고정된 스킬 프로그램만 동작하며 IS는 직접 개입하지 않는다.
- 평가 단계(아래의 내용을 반복)
- 테스트 상황을 생성
- 평가되는 스킬 프로그램이 응답을 생성
- 점수 평가 함수가 생성된 응답에 점수를 부여(피드백은 폐기)
- 받은 응답을 기반으로 내부 상태 업데이트
- 마찬가지로 SituationGen 함수의 판단 하에 종료
지금까지의 설명을 기반으로 아래의 개념들을 정의한다.
- 평가 결과(Evaluation result) : 하나의 스킬 프로그램이 특정 작업의 평가 단계에서 얻은 점수의 총합
- 스킬(Skill) : 평가 상황들의 모든 가능한 경우를 고려한 평가 결과들의 평균 값
- 최적 스킬(Optimal skill) : 특정 작업에서 이론적으로 가능한 최대의 스킬
- 충분 스킬 임계값 $\theta_T$(Sufficient skill threshold) : 작업을 해결했다고 판단할 수 있는 최소한의 스킬 기준
- 작업 및 스킬 가치 함수(Task and skill value function) : 작업과 기술 수준의 조합에 따라 가치($\omega_{T,\theta}$)를 부여하는 함수, 스킬이 높을수록 가치가 높아짐
- 작업 가치 $\omega_T$(Task value) : 특정 작업에서 임계값 $\theta_T$ 달성 시 얻는 가치
- 최적해(Optimal solution) : 특정 작업에서 최적의 스킬을 달성하는 스킬 프로그램
- 충분해(Sufficient solution) : 특정 작업에서 임계값 $\theta_T$를 넘는 스킬을 달성하는 스킬 프로그램
- 커리큘럼(Curriculum) : 작업과 지능 시스템 간의 훈련 상호작용을 포함하는 학습 과정
- 최적 커리큘럼(Optimal curriculum) : 시스템이 특정 작업에 대해 가능한 가장 높은 스킬을 얻게 해주는 학습 과정
- 충분 커리큘럼(Sufficient curriculum) : 시스템이 특정 작업의 임계값을 넘는 스킬을 얻게 해주는 학습 과정
- 작업-특화 잠재력 $\theta^\max_{T, IS}$ : 특정 작업에서 지능 시스템이 최적 커리큘럼을 통해 도달할 수 있는 최대 스킬 값.
- 지능 시스템 범위(Intelligent system scope) : 시스템이 충분한 해를 만들어 낼 수 있는 모든 작업들의 집합
- 지능 시스템 잠재력(Intelligent system potential) : 시스템의 범위 내 모든 작업들에 대한 작업 특화 잠재력의 종합
Quantifying generalization difficulty, experience, and priors using Algorith-mic Information Theory
알고리즘 정보 이론(Algorithmic Information Theory, AIT)은 정보 이론의 개념을 컴퓨터 과학적으로 확장하여 복잡성, 무작위성, 정보, 계산 등의 개념을 엄밀히 다루는 이론이다. 정보 이론의 엔트로피와 비슷하게 여기서는 정보량을 나타내는 척도로 복잡성을 사용한다.
- 알고리즘 복잡성 : 문자열을 생성하는 가장 짧은 프로그램의 길이 $H(s)$, 해당 문자열의 정보량을 나타냄
- 상대적 알고리즘 복잡성 : 문자열 $s_2$를 입력받아 $s_1$을 출력하는 가장 짧은 프로그램의 길이
모든 프로그램이 이진 문자열로 표현 가능하므로 상대적 알고리즘 복잡성을 활용해 두 프로그램의 관계를 파악할 수 있다. 이를 바탕으로 과제의 일반화 난이도(Generalization Difficulty)라는 개념을 다음과 같이 정의한다:
- 과제 $T$
- $Sol^\theta_T$ : 임계값 $\theta$를 만족하는 가능한 $T$의 해답 중에서 가장 짧은 것
- $TrainSol^\text{opt}_{T,C}$ : 주어진 커리큘럼에서 최적의 학습 시간 성능을 달성하는 최단 스킬 프로그램
일반화 난이도(Generalization Difficulty) : 주어진 커리큘럼 $C$와 특정 스킬 수준 $\theta$에 대해 훈련 상황에서 최적이었던 프로그램을 실제 평가 상황에서도 잘 작동하도록 수정하는 데 필요한 정도를 나타낸 값이다.
$$GD^\theta_{T,C} = \frac{H(Sol^\theta_T|TrainSol^\text{opt}_{T,C})}{H(Sol^\theta_T)}$$
- $Sol^\theta_T$ : 평가 상황에서 목표 수준 $\theta$ 이상의 성능을 내는 가장 짧은 스킬 프로그램
- $TrainSol^\text{opt}_{T,C}$ : 주어진 훈련 상황에서 최적의 성능을 내는 가장 짧은 스킬 프로그램
- $H(\cdot)$ : 프로그램 길이를 나타내는 알고리즘 복잡도
- 이 값이 높을수록, 훈련 상황에서 최적인 프로그램을 평가 상황에 맞게 수정하는 데 더 많은 변경이 필요함 → 즉, 일반화가 어렵다
- 값이 낮으면, 훈련 상황에서 만든 최적 프로그램이 평가 상황에서도 잘 작동함 → 일반화가 쉽다
개발자 인지적 일반화 난이도(Developer-aware Generalization Difficulty) : 지능 시스템이 주어진 훈련 커리큘럼에서 최적의 성능을 내는 가장 간단한 프로그램에서 평가 단계에서 충분한 성능(임계값 $\theta$)을 달성하는 최단 프로그램까지의 수정 정도
$$GD^\theta_{IS,T,C} = \frac{H(Sol^\theta_T|TrainSol^\text{opt}_{T,C}, IS_{t=0})}{H(Sol^\theta_T)}$$
- 여기서 값은 0과 1 사이이며, 값이 높을수록 평가 단계에서 필요한 일반화의 난이도가 큼
- 또 다른 일반화 난이도의 정의로, 한 과제에서 다른 과제로의 일반화 난이도를 정의할 수도 있고, 이것은 특정 과제 집합 전체의 일반화 난이도를 평가하는 데 유용하게 활용 가능
사전지식(Priors) : AI가 학습을 시작하기 전 이미 작업 해결에 관련된 정보를 얼마나 가지고 있는지를 나타냄
$$P^\theta_{IS,T} = \frac{H(Sol^\theta_T) - H(Sol^\theta_T| IS_{t=0})}{H(Sol^\theta_T)}$$
- 시스템이 최적의 해결책에서 얼마나 가까운 위치에서 출발하는지를 측정
경험(Experience)
- AI가 학습 중에 태스크 해결을 위해 실제로 얻는 유용한 정보의 양을 나타냄
- 학습 중 관련 정보와 새로운 정보를 구분하며, 새로운 정보가 많을수록 학습 효과가 높아짐
- 한 학습 단계에서 AI가 얻는 불확실성 감소량을 통해 측정됨
1. 특정 단계에서의 경험(Experience accrued at step $t$)
$$E^\theta_{IS,T,t} = H(Sol^\theta_T|IS_t) - H(Sol^\theta_T| IS_t,data_t)$$
- AI가 특정 학습 단계에서 받은 데이터가 문제 해결에 기여한 정보량을 측정
- 높은 값일수록 AI가 해당 단계에서 많은 학습을 함
2. 전체 학습 커리큘럼에서의 경험
$$E^\theta_{IS,T,C} = \frac{1}{H(Sol^\theta_T)}\sum_{t}E^\theta_{IS,T,t}$$
- 학습 과정 전체에서 AI가 축적한 유의미한 정보량의 총합
- 불필요한 반복 학습을 페널티 없이 고려하며, 정보의 질을 평가
Defining intelligence
시스템의 지능은 특정 작업 범위(scope) 내에서 기술을 얼마나 효율적으로 습득하는가를 측정하는 값이다. 이는 사전 지식(priors), 경험(experience), 일반화 난이도(generalization difficulty)를 고려하여 평가된다.
1. 충분한 기술 수준을 고려한 지능(Sufficient Case)
$$I^{\theta_T}_{IS,scope} = \underset{T \in scope}{Avg}\left [\omega_T \cdot \theta_T \sum_{C \in Cur^{\theta_T}_T} \left [P_C \cdot\frac{GD^{\theta_T}_{IS,T,C}}{P^{\theta_T}_{IS,T} + E^\Theta_{IS,T,C}}\right ] \right ]$$
2. 최적 기술 수준을 고려한 지능(Optimal Case)
$$I^{opt}_{IS,scope} = \underset{T \in scope}{Avg}\left [\omega_{T, \Theta} \cdot \Theta \sum_{C \in Cur^{opt}_T} \left [P_C \cdot\frac{GD^{\Theta}_{IS,T,C}}{P^{\Theta}_{IS,T} + E^\Theta_{IS,T,C}}\right ] \right ]$$
- $ P_{IS,T} + E_{IS,T,C}$ : 시스템이 특정 작업에 대해 보유한 전체 정보(사전 지식 + 경험)
- $\sum P_C$ : 특정 기술 수준을 달성하는 커리큘럼 확률의 합, 낮을수록 해당 기술 수준을 달성하는 것이 어려움
- $\omega_T \cdot \theta_T$ 및 $\omega_T \cdot \Theta$ : 특정 기술 임계값을 달성하는 것의 상대적 중요도
- 최종적으로 작업의 기여도는 $Expectation[\frac{skill-generalization}{priors + experience}]$
우리는 지능을 주어진 정보를 얼마나 효율적으로 활용하여 최종 기술 수준에 도달하는가를 측정하는 값으로 정의한다. 기존의 AIT 기반 지능 정의인 C-Test, AIXI, Universal Intelligence와 우리의 정의는 다르다(그림 3 참고).
- 높은 지능을 가진 시스템
- 적은 경험과 사전 지식만으로도 불확실한 환경에서 높은 성과를 낼 수 있는 시스템
- 일반화 난이도가 높은 작업에서 적응 가능해야 함
- 지능과 기술의 차이
- 기술(skill)과 지능(intelligence)은 동일하지 않음
- 기술은 지능이 만들어낸 결과물이며, 높은 기술이 높은 지능을 의미하지는 않음
- 지능의 필수 조건
- 처음부터 특정 작업을 수행할 수 있는 시스템은 일반화 난이도가 낮아 지능 점수가 낮음
- 지능이란, 주어진 정보를 이용해 미래의 불확실성에 대비하는 능력
- 지능과 커리큘럼 최적화의 관계
- 더 좋은 학습 커리큘럼 → 더 높은 기술 습득 → 더 높은 지능 표현
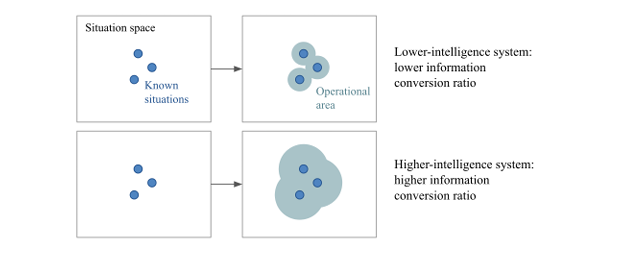
우리의 정의에 따르면 지능은 단순히 높은 기술을 가지는 것이 아니라 최소한의 정보로도 불확실한 미래 환경에서 효과적으로 적응하고 학습하는 능력을 의미한다. 불확실성이 높은 상황에서 적은 정보로도 강한 일반화 능력을 발휘하는 시스템이 진정으로 높은 지능을 가진다.
Computation efficiency, time efficiency, energy efficiency, and risk efficiency
이전까지는 정보 효율성(사전 지식 및 경험을 통한 일반화 능력)을 중심으로 지능을 평가했지만, 계산 비용, 시간, 에너지, 위험 회피 등 다른 측면도 고려할 수 있다.
특히, 위험을 줄이거나 자원을 절약하는 방식으로 지능을 정의하는 것이 특정 AI 응용 분야에서 중요해질 것이며, 앞으로 연구자들이 이러한 요소를 포함하는 새로운 지능 정의를 개발할 필요가 있다.
Practical implications
이 논문은 기존 AI 개념에서 벗어나, 지능이란 정보를 얼마나 효율적으로 새로운 기술로 변환할 수 있는가라는 관점에서 정의한다. 이를 통해 AI 연구 및 평가 방식에 실질적인 변화를 초래할 수 있는 여러 가지 핵심적인 실천 방향을 제시한다.
- 연구 방향:
- AI 개발을 최적화 문제로 접근 가능
- 특정 기술이 아닌 일반적 능력 개발을 장려
- AI를 블랙박스가 아닌 프로그래밍 합성 관점에서 접근
- 최적 커리큘럼 개념 활용
- 인간과 유사한 사전 지식 연구 촉진
- 평가 방법:
- AI 일반화 능력을 공식적으로 정의 및 평가
- AI와 인간 지능 비교 기준 제공
- 테스트 세트에서 일반화 난이도를 필수 고려
- AI 시스템 평가 시 필수적으로 고려해야 할 질문들 제시
이러한 접근 방식은 AI가 단순한 스킬 실행이 아니라, 불확실성과 적응이 필요한 새로운 환경에서도 능력을 확장할 수 있는 방식으로 발전하도록 유도하는 것을 목표로 한다.
Evaluating intelligence in this light
이 문서는 AI 평가에서 단순한 기술력(skill) 비교가 아닌 일반화 능력을 측정해야 한다고 강조한다. 이를 위해 심리측정학(psychometrics)의 개념을 도입하고 새로운 공식화(formalism)를 제시한다.
Fair comparisons between intelligent systems
AI 시스템 비교를 위한 핵심 요소
- 적용 범위(Scope): 모든 비교 대상 AI 시스템이 동일한 작업을 학습할 수 있어야 함
- 기술 임계치(Skill Threshold): 비교 대상 AI가 도달할 수 있는 특정 기술 수준이 동일해야 함
- 사전 지식(Priors): 비교 가능한 수준의 사전 지식을 보유해야 함
공정한 AI 지능 비교 방법
- 기술 습득 효율성(skill-acquisition efficiency)을 비교, 더 적은 경험(experience)으로 동일한 기술 수준에 도달하는 AI가 더 높은 지능을 가진 것으로 평가
- 필요에 따라 계산 효율성, 에너지 효율성, 위험 효율성 등의 추가 요소 고려 가능
What to expect of an ideal intelligence benchmark
AI 평가 벤치마크는 아래와 같은 조건이 필수적이다.
- 적용 범위 & 예측력
- 벤치마크의 적용 범위를 명확히 정의하고, 실제 작업 성공률과의 통계적 관계를 입증해야 함
- 신뢰성 (재현 가능성)
- 확률적 요소가 평가 결과에 큰 영향을 주지 않도록 보장
- 독립적인 연구자들이 동일한 평가 결과를 얻을 수 있어야 함
- 넓은 범위의 능력 및 일반화 측정
- 단순한 기술(skill)이나 최대 성취 가능 기술만 측정해서는 안 됨
- AI 시스템과 개발자가 사전에 알지 못하는 새로운 작업을 포함해야 함
- 일반화 난이도(local, broad, extreme)를 명확히 정의하여 편법 학습을 방지해야 함
- 경험량(experience) 통제
- 무제한 데이터 샘플링을 통한 인위적 성능 향상을 방지해야 함
- 사전 연습이 불가능한 게임 형태의 문제를 포함하는 것이 바람직함
- 사전 지식(Priors) 명확화
- 암묵적인 사전 지식을 명확히 정의하고 문서화해야 함
- 인간과 AI 모두에게 공정해야 함
- Core Knowledge 수준의 선천적 사전 지식만 가정해야 함
- 인간이 필요로 하는 수준의 연습 시간과 훈련 데이터만 요구해야 함
Abenchmark proposal: the ARC dataset
여기서는 Abstraction and Reasoning Corpus(ARC)를 소개한다. 앞에서 정의한 일반 지능(general intelligence)을 벤치마킹하기 위한 데이터셋이다.
Description and goals
What is ARC?
ARC는 다음과 같은 방식으로 정의할 수 있다.
- 일반 AI 평가, 프로그램 합성 평가, 심리측정 지능 테스트를 위한 데이터셋
- 인간과 인간 유사 AI 시스템을 대상으로 함
- Raven's Progressive Matrices와 유사한 형식
ARC의 목표
- 특정 훈련 없이도 인간이 해결할 수 있도록 설계
- 사전에 알려지지 않은 새로운 작업만 포함하여 일반화 능력 평가
- 소수의 예제만으로 고도로 추상적인 문제 해결 필요
- 훈련 데이터 양을 제한하여 경험을 정량적으로 통제
- AI와 인간이 공정하게 비교될 수 있도록 인간과 유사한 사전 지식만 요구
ARC의 데이터 구성
- 훈련 셋(400개)와 평가 셋(600개)로 구성
- 평가 셋은 공개와 비공개로 나뉨
- GitHub에서 데이터 제공
작업(Task) 구조
- 각 작업은 평균 3.3개의 예제와 1개의 테스트 예제를 포함
- 입력 격자를 통해 출력 격자로 변환이 필요(그림 4 참고)
- 격자는 최대 30 x 30 크기, 10개의 고유한 색상 사용
평가 방법
- 테스트 예제당 3번의 시도 가능(정답과 오답 피드백 제공)
- 평가 점수는 성공적으로 해결한 작업의 비율
- AI 개발자도 사전에 평가 셋을 알 수 없기에 공정한 일반화 측정이 가능
훈련 셋 역할
- AI의 검증(validation)과 인간 모의 테스트 용도
- Core Knowledge 개념 학습을 위한 자료로 활용 가능
- 훈련 셋 연습이 인간 성능 향상에 영향을 미치는지는 연구 필요

Core Knowledge Priors
모든 지능 테스트는 선행 지식을 포함할 수밖에 없다. ARC는 Core Knowledge 기반의 선행 지식만 사용하도록 설계되었으며 이를 통해 인간과 AI의 공정한 비교가 가능하다.
- 개체 관련 선행 지식
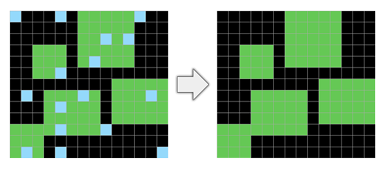
- 개체 응집성(Object cohesion) : 연속성(색상/공간적 인접성) 기준으로 개체 인식 가능(그림 5 참고)
- 개체 지속성(Object persistence) : 노이즈(그림 6 참고)나 가림에도 개체가 유지됨을 가정
- 접촉을 통한 개체의 영향(Object influence via contact) : 개체 간 물리적 접촉이 작업에 영향을 미침(그림 7, 그림 8 참고)

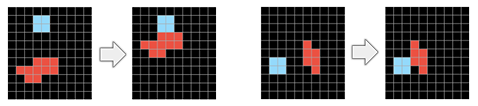
- 목표 지향성(Goal-directedness) 사전 지식
- ARC에는 시간 개념이 존재하지 않음
- 그래도 많은 입력/출력 격자가 의도적인 과정의 시작과 끝 상태로 모델링 가능(그림 9 참고)
- 숫자 및 계산(Number and Counting) 사전 지식
- ARC의 많은 작업은 객체를 세거나 정렬하는 것을 포함
- 개수 비교(그림 10 참고), 정렬, 덧셈/뺄셈, 판복 패턴
- 기하학 및 위상학(Geometry and Topology) 사전 지식
- ARC 작업에는 기본적인 기하학 및 위상학 개념이 포함
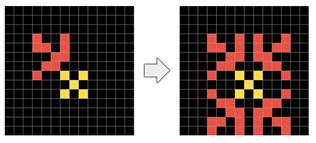
- 선, 대칭(그림 11 참고), 회전, 포함 관계, 객체 복사/반복 등

Key differences with psychometric intelligence tests
ARC는 전통적인 IQ 테스트 형식과 유사하지만 본질적으로 중요한 차이점을 갖는다.
- ARC는 유동적 지능(추론과 추상화)만 평가, 언어/현실 상식을 포함하지 않는다
- 고유한 문제 셋을 제공하여 개발자의 사전 학습 및 하드코딩을 방지한다.
- 수백 개의 독창적인 문제를 제공하여 특정 유형만 하드코딩하는 것이 비효율적이다.
- 문제를 수작업으로 생성하여 예상치 모산 편법을 사전에 차단한다.

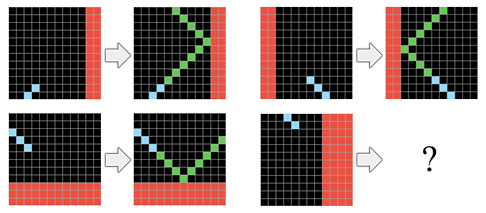
What a solution to ARC may look like, and what it would imply for AI applications
높은 IQ를 가진 실험 참가자 3명 중 최소 1명이 모든 ARC 과제를 해결하는 것으로 인간이 해결 가능함을 검증하였다. ARC는 기존의 기계학습 기법으로 해결이 어려운데 그 이유는 광범위한 일반화와 소량 학습이 필요하기 때문이다. 또한 평가 셋에는 훈련 셋에 없는 완전히 새로운 과제만 포함되어 있다.
ARC 해결을 위한 가설적 접근법은 아래와 같다.
- 도메인 특화 언어(DSL) 개발
- 모든 ARC 과제를 표현할 수 있는 추론 및 조합 가능한 언어 개발
- 핵심 지식(Core Knowledge) priors를 DSL의 기본 요소로 설계
- 후보 프로그램 생성
- DSL을 사용해 입력과 출력 변환 프로그램 후보군 생성
- 기존 과제에서 유용했던 하위 프로그램(subprogram) 재사용 및 조합
- 최적의 프로그램 선택
- 단순성(simplicity) 및 확률(likelihood) 기준으로 최적 후보 선별
- 단순한 프로그램이 항상 일반화에 적합하지 않음(일반화 난이도 고려)
- 테스트 예제의 출력 생성
- 최적 후보 3개를 활용해 정답 생성
ARC를 해결하는 AI는 인간과의 상호작용이 쉬운 AI가 될 가능성이 있지만 Newell의 체스 AI 연구처럼 인지 능력으로 이어질지는 불확실하다. 향후 연구를 통해 ARC의 가치가 검증될지, 아니면 무의미한 것으로 판명날지 결정될 것이다.
Weaknesses and future refinements
ARC의 주요 한계
- 일반화 난이도 정량적 측정 부족
- 테스트 유효성 미확립
- 데이터셋 크기 및 다양성 제한
- 평가 방식이 지나치게 폐쇄적이고 이진적
- Core Knowledge priors 정의 불명확
향후 연구 방향
- 일반화 난이도 정량적 측정 연구
- 대규모 인간 실험 진행 및 AI ARC 솔버 성능 검증
- AI 경진대회 개최하여 문제 단순 해결 방식 존재 여부 검증, 새로운 과제 지속적으로 추가
- 반복적 학습 환경 제공하여 피드백을 통한 학습 가능하도록 개선
- ARC가 실제로 인간의 선천적 지식만을 평가하는지 검증 및 연구
Possible alternatives
ARC는 인간과 유사한 범용 인공지능을 평가하는 벤치마크를 만들기 위한 하나의 시도일 뿐이다. 다른 다양한 접근 방식도 고려할 수 있으며 몇 가지 제안을 제시해보고자 한다.
Repurposing skill benchmarks to measure broad generalization
기존 게임 AI에서는 게임 내 학습한 데이터와 동일한 레벨 또는 유사한 환경에서 평가가 이뤄지기 때문에 지역적 일반화만 평가하고 새로운 환경에서의 광범위한 일반화 능력을 측정하지 못한다.
이를 해결하기 위해 변형 게임을 설계하여 기존 AI의 일반화 능력을 평가한다. 변형 게임은 단순히 새로운 레벨이 아니라 기존 학습 데이터들로 해결할 수 없는 새로운 규칙과 게임 플레이를 포함한다. 그렇기에 진정한 의미에서의 일반화 평가가 가능하다.
예를 들어 도타2에서 학습한 AI를 League of Legends나 Heroes of the Storm과 같은 유사한 장르에서 얼마나 빨리 학습하는지 평가를 진행한다.
Open-ended adversarial or collaborative approaches
수작업으로 문제를 만드는 방식은 비효율적이며 확장성이 부족하다. 그렇다고 프로그래밍을 통해 자동으로 새로운 과제를 생성할 경우 다양성과 복잡성의 한계가 생기며 벤치마크를 속이는 방식이 존재할 가능성이 있다.
교사와 학생을 나누는 새로운 시스템 방식을 제안한다(그림 12 참고).
- 교사 프로그램 : 새롭고 도전적인 문제를 지속적으로 생성
- 학생 프로그램 : 점점 더 어려운 문제를 해결하며 학습
- 교사는 학생의 효율을 극대화하는 방식으로 과제를 조절 가능, 커리큘럼 최적화 가능
교사 프로그램이 외부(real-world) 데이터를 활용하여 과제를 생성하면 더욱 복잡하고 현실적인 문제를 반영할 수 있다. 결과적으로, 학생 프로그램이 인간이 해결해야 하는 실제 문제에도 적용 가능하도록 학습할 수 있을 가능성이 존재한다.

'GIST > Artificial General Intelligence' 카테고리의 다른 글
| [AGI] ARC-AGI Without Pretraining(by Isaac Liao) (0) | 2025.04.07 |
|---|---|
| [AGI] Program Synthesis - 4 (0) | 2025.04.03 |
| [AGI] Program Synthesis - 3 (0) | 2025.04.03 |
| [AGI] Program Synthesis - 2 (0) | 2025.04.02 |
| [AGI] Program Synthesis - 1 (0) | 2025.04.02 |