Introduction
강력한 비선형 함수 근사기와 강화학습의 결합은 순차적 의사결정 문제에서 다양한 발전을 가져왔다. 그러나 기존의 RL 방법들은 각 과제마다 별도의 정책을 학습하며, 이는 종종 환경과의 수백만 회에 이르는 상호작용을 필요로 하며 비용적으로 부담이 발생한다.
다행히 우리가 자율 에이전트에게 해결하도록 원하는 많은 과제들은 공통된 구조를 공유한다. 예를 들어 병뚜껑을 돌려서 닫는 일과 문손잡이를 돌리는 일은 모두 물체를 손에 움켜쥐고 손목을 회전시키는 동작을 포함한다. 메타러닝 방법들은 방대한 경험을 활용하여 이런 구조를 경험적으로 학습한다. 학습이 완료되면 이 방법들은 적은 양의 경험만으로 새로운 과제에 빠르게 적응이 가능하다.
메타러닝으로 학습된 정책들은 소수의 시도만으로 새로운 과제에 적응할 수 있지만 메타학습 단계에서 여전히 방대한 양의 데이터를 필요로 한다. 현재 대부분의 meta-RL 방법은 메타 훈련 및 적응에서 모두 on-policy 데이터를 요구하여 훈련이 비효율적이다. off-policy 데이터를 활용하는 것은 on-policy와 달리 탐색 데이터 분포를 직접 제어하지 못하기 때문에 효과적인 탐색을 위한 추가적인 메커니즘이 필요하다.
본 논문에서는 효율적인 off-policy meta-RL 문제를 해결하고자 한다. 메타 훈련 효율성과 빠른 적응을 모두 달성하기 위해, 확률적 컨텍스트 변수의 온라인 추론을 기존 off-policy RL 알고리즘과 통합하는 접근 방식을 제안한다.
- off-policy meta-RL : 기존 off-policy RL과 확률적 컨텍스트 변수의 온라인 추론을 통합
- 확률적 인코더 : 과거 경험을 통해 컨텍스트 변수를 학습하여, 메타-테스트 시 task 가설을 샘플링하고 탐험 후 사후 분포를 갱신
- 행동과 과제 추론 분리 : 정책 최적화는 off-policy로, 컨텍스트 인코딩은 on-policy로 수행하여 분포 불일치 최소화
본 논문은 Probabilistic Embeddings for Actor-critic meta-RL(PEARL)을 제시했다. 이 방법은 메타 훈련 중 뛰어난 샘플 효율성을 달성하고 온라인으로 경험을 축적하여 빠른 적응을 가능하게 하며, 태스크 불확실성에 대한 추론을 통해 구조화된 탐색을 수행한다. 실험 평가에서는 메타학습의 6개 도메인에서 선행 연구 대비 20~100배 향상된 최종 성능 상승을 보였다.
Related Work
Meta-learning
다양한 meta-RL 방법들이 개발되고 있다.
- 순환적 및 재귀적 meta-RL : 정책이 의존하는 잠재 표현 속으로 경험을 집계함으로써 새로운 과제에 적응
- 본 논문의 접근법(PEARL) : 확률적 잠재 변수를 사용하여 과제의 불확실성에 대한 추론이 가능
- Duan et al., James et al. : 컨텍스트 기반 접근법으로 시연 기반 학습에 적용하여 시연 데이터를 임베딩하고 그 위에 정책을 조건화하여 행동 cloning으로 최적화하는 데 사용
- 경사 기반 meta-RL : 경험을 집계하여 정책 경사, 메타학습된 손실 함수, 또는 하이퍼파라미터 등을 통해 학습, 대부분 on-policy에 집중
본 논문에서는 off-policy 데이터 기반 메타러닝에 초점을 맞추며, 이는 정책 경사법이나 진화 최적화 알고리즘 기반 방법으로 수행하기에는 간단하지 않은 문제이다. 우리는 단순히 표본 효율성을 크게 향상시킨 것에 그치지 않고, 실험적으로도 정책 경사 기반 방법들보다 더 높은 수렴 성능을 달성함을 확인했다.
본 논문에서는 확률적 임베딩을 사용하여 강화학습 에이전트의 행동을 조건화한다. 이렇게 제안한 이 임베딩 함수는 meta-RL 맥락에서 지금까지 제안된 적이 없는 것으로 보인다.
Probabilistic meta-learning
이전 연구들은 확률적 모델을 지도 메타러닝과 RL 메타러닝에 모두 적용했다. Hierarchical Bayesian 모델은 소수샷 학습을 위해 사용되었고 이는 경사 기반 적응 방법을 포함한다. 지도학습에서는 모델 예측을 확률적 잠재 작업 변수를 이용하여 적응했다. 우리는 이런 아이디어를 off-policy meta -RL에 적용했다. multi-task RL의 컨텍스트에서 작업 변수에 관련된 정책을 조건화했지만 목표는 임베딩 공간을 구성하는 것이었으며 우리는 새로운 작업에 대한 빠른 적응에 집중했다. 우리가 작업 변수에 대해 추론하고 사전 샘플링을 통해 탐험할 때 MAESN은 작업 변수를 경사 하강법을 통해 최적화를 진행했다.
Posterior sampling
고전적인 RL에서는 posterior sampling이 가능한 MDP들에 대한 사후 분포를 유지하고 샘플링된 MDP에 대해 최적의 방식으로 행동함으로써 시각적으로 확장된 탐색을 가능하게 한다. 우리의 접근 방식은 이런 방법의 메타러닝 버전으로 해석이 가능하다. 확률적 컨텍스트는 현재 작업에 대한 불확실성을 포착하며, 이를 통해 에이전트는 새로운 작업에서도 유사한 구조로 탐색이 가능하다.
Partially observed MDPs
meta-RL에서 테스트 시점의 적응은 작업을 관측되지 않은 상태의 일부로 포함함으로써 POMDP에서의 강화학습의 특수한 경우로 해석될 수 있다. 우리는 lgl et al. 과 관련된 변분 추론 기반 접근을 사용하여 작업에 대한 신념을 추정한다. 그들은 일반적인 POMDP 문제를 해결하는 데 초점을 맞춘 반면, 우리는 메타러닝 문제에 내재된 구조적 제약을 활용해 추론을 단순화하고 새로운 작업에 대한 탐색에는 posterior sampling을 사용한다.
Meta-RL Problem Statement
우리는 에이전트가 이전 작업을 통해 새로운 작업에 빠르게 적응하는 다양한 경험을 활용하는 상황에서 동기를 얻었다. 샘플 효율성은 우리의 문제 설정에서 핵심적인 요소로, 이전 경험에서 얻은 샘플 수와 새로운 작업에서 필요한 경험의 양 두 측면을 모두 포함한다. 우리는 메타학습 효율성을 off-policy RL을 활용해서 진행했다. 적응 효율성을 위해서는 특히 보상이 희소한 환경에서 에이전트가 자신이 맡은 작업에 대한 불확실성을 추론할 수 있어야 한다. 작업에 대한 불확실성을 포착하기 위해 우리는 이전 경험으로부터 확률적인 잠재 표현을 학습한다.
이전의 meta-RL 제형과 비슷하게 우리는 작업에 대한 분포 $p(\mathcal{T})$를 가정했다:
- 각 작업은 MDP로 이뤄짐
- states, actions, transition function, reward function으로 구성
- transition과 reward 함수는 알려지지 않음, 그러나 환경에서 액션을 수행하여 샘플링 가능
공식화하면 작업 $\mathcal{T} = \{p(s_0), p(s_{t+1}|s_t,a_t), r(s_t,a_t)\}$은 아래 구성요소로 이뤄져 있다:
- $p(s_0)$ : 초기 상태
- $p(s_{t+1}|s_t,a_t)$ : transition 분포
- $r(s_t,a_t)$ : 보상 함수
이러한 문제 정의는 다양한 전환 함수를 가진 작업 분포와 다양한 보상 함수를 포함한다. $p(\mathcal{T})$에서 샘플링된 훈련 분포가 주어지면 메타 훈련 과정은 과거 전이 이력, 즉 컨텍스트 c를 이용하여 적응할 수 있는 정책을 학습한다.
- $\mathbb{c}^\mathcal{T}_n = (s_n, a_n, r_n, s'_n)$ : 작업의 전이 중 하나
- $\mathbb{c}^\mathcal{T}_{1:N}$ : 지금까지 수집된 경험
이를 이용하여 테스트 시점에 정책은 새로운 작업에 대해 적응하도록 한다.
Probabilistic Latent Context
우리는 현재 작업을 어떻게 수행해야 하는지에 대한 지식을 잠재 확률적 컨텍스트 변수 $Z$에 담고, 이 변수에 조건화된 정책 $\pi_\theta(a|s,z)$을 통해 작업에 맞게 행동을 적응시킨다. 메타 학습은 다양한 훈련 작업들로부터 얻은 데이터를 활용하여, 새로운 작업에서의 최근 경험 이력을 바탕으로 $Z$의 값을 추론하는 방법을 학습하는 동시에, 이 $Z$의 사후 분포로부터 샘플링된 값에 기반해 주어진 작업을 해결할 수 있도록 정책을 최적화하는 것이다.
Modeling and Learning Latent Contexts
적응을 가능하게 하기 위해서는 잠재 컨텍스트 $Z$는 반드시 작업에 대한 두드러진 정보를 해독해야 한다. 위에서 나왔던 $\mathbb{c}^\mathcal{T}_{1:N}$를 다시 불러보자. 이 파트에서는 해당 식을 $c$를 간단하게 적을 것이다.
우리는 적응하기 위해 추론 방법을 사용하여 $Z$를 추론하는 법을 학습했다.
- 추론 네트워크 $q_\phi(z|c)$를 학습
- $\phi$ : 파라미터화하는 변수
- 사전분포 $p(z|c)$를 추정
생성적 접근 방식에서는 $q_\phi(z|c)$를 보상과 동역학에 대한 예측 모델을 학습함으로써 MDP를 재구성하는 방식으로 최적화할 수 있다. 대신 우리는 $q_\phi(z|c)$를 model-free 방식으로 최적화하는 방식을 사용했다. 목적 함수는 log-likelihood로 표현되며 아래와 같다:
$$\mathbb{E}_\mathcal{T}[\mathbb{E}_{z\sim q_\phi(z|c^\mathcal{T})}[R(\mathcal{T},z) + \beta D_{KL}(q_\phi(z|c^\mathcal{T})\parallel p(z))]]$$
- $p(z)$ : $Z$에 대한 단위 가우시안 사전부포
- $R(\mathcal{T}, z)$ : 다양한 학습 목표를 나타내는 함수
- KL 발산 부분 : $Z$와 $c$사이의 상호 정보량을 제약하는 정보 병목 최적화로 해석 가능
- 병목은 $z$를 적응하기 위해 필수적인 컨텍스트에 대한 정보만을 포함하도록 하며, 훈련 작업에 과적합되는 것을 완화시킴
- $q_\phi$ : 메타 학습중에 최적화되고 수정
- 테스트 시점에는 수집된 경험으로부터 단순히 $Z$만 추정
추론 네트워크 $q_\phi(z|c)$의 구조를 설계하기 위해 우리는 작업(task)과 관련된 정보를 표현하기에 충분히 표현력이 있는 동시에, 불필요한 종속성은 모델링하지 않도록 설계하고자 한다.
완전히 관찰된 MDP의 인코딩은 $\{s_i,a_i,s'_i,r_i\}$들의 순서와 무관한 집합으로 표현할 수 있다. 그렇기에 전이 함수와 보상 함수는 정렬되지 않은 전이 집합으로부터 다시 만들 수 있다.
이로부터 전이 집합 하나만으로도 가치 함수를 학습하거나 해당 작업이 무엇인지를 추론하는 데 충분함을 알 수 있다. 이런 관찰을 바탕으로 우리는 추론 네트워크를 아래와 같이 모델링한다:
$$q_\phi(z|c_{1:N}) \propto \Pi^N_{n=1}\Psi_\phi(z|c_n)$$
- $\Psi_\psi(z|c_n) = \mathcal{N}(f^\mu_\phi(c_n),f^\sigma_\phi(c_n))$
- $f_\phi$ : $\phi$에 의해 파라미터화된 뉴럴 네트워크
- 평균 $\mu$와 분산 $\sigma$, $c_n$의 함수를 예측
- 그림 1에서 확인할 수 있음

Posterior Sampling and Exploration via Latent Contexts
잠재 컨테스트를 확률적으로 모델링하는 것은 테스트 시점에 사전 샘플링을 통해 탐색 효율성을 올려준다. RL에서 posterior sampling은 MDP의 사전 분포로 시작하여 현재까지의 경험을 조건으로 사후 분포를 추론하고, 샘플링된 MDP에서 수집된 최적의 정책을 에피소드 전체에 걸쳐 수행함으로써 시간적 으로 확장된 탐색을 가능하게 한다.
단일 작업 deep RL 설정에서는 사전 샘플링과 deep 탐색의 이익은 Osband et al.에 의해 탐색되었으며 부트스트래핑을 통해 가치 함수에 대한 사후 분포를 근사하는 방식을 제안했다. 그러나 우리의 방법인 PEARL은 잠재 컨텍스트 $Z$에 대한 사후 분포를 직접 추론한다:
- $Z$는 재구성 목적이라면 MDP 자체를
- 정책 최적화 목적이라면 최적 행동을
- 가치 기반이라면 가치 함수를 포함하도록
학습될 수 있다.
메타 학습 과정에서는 다양한 훈련 작업을 통해 작업 분포를 포착하는 사전 분포를 학습하고, 새로운 작업에 빠르게 적응하기 위한 추론 방식도 함께 학습한다. 테스트 시점에 우리는 여러 개의 샘플 $z$를 샘플링하여 에피소드를 실행하고 이 경험을 바탕으로 사후 분포를 업데이트 한다. 이를 통해 점점 더 정확한 탐색 및 행동을 수행하게 된다.
Off-Policy Meta-Reinforcement Learning
우리의 확률적 컨텍스트 모델은 on-policy 경사 하강법과 쉽게 결합할 수 있지만 우리의 최종 목표는 소수의 샘플로도 메타 학습과 빠른 적응이 가능한 효율적인 off-policy meta-RL을 가능하게 하는 것이다. 기존 연구들은 안정적이지만 비효율적인 on-policy 알고리즘에 의존해 메타 학습 효율성을 크게 고려하지 않았다.
그러나 off-policy meta-RL을 설계하는 것은 간단하지 않다. 현대 메타러닝은 메타 학습과 테스트에서 적응에 사용하는 데이터 분포가 일치한다는 전제에 기반하고 있다. 이는 테스트 시점에 on-policy 데이터로 적응해야 한다면, 메타 학습 중에도 동일하게 on-policy 데이터를 사용해야 함을 의미한다.
게다가, meta-RL은 분포 수준의 추론이 요구되며, 효과적인 확률적 탐색 전략을 학습해야 한다.
- TD 오류를 최소화 하는 off-policy RL : 방문 상태의 분포를 직접 최적화할 수 업식에 문제를 해결할 수 없음
- 정책 경사법 : 정책이 취할 행동에 직접 개입할 수 있으므로 요구를 만족시킬 수 있음
이런 두 가지 도전 과제(분포 불일치 문제와 탐색 제약) 때문에 단순히 메타러닝과 가치 기반 RL을 결합하는 방식은 비효율적이며, 실제로 우리는 해당 접근을 성공적으로 최적화하지 못했다.
우리는 잠재 컨텍스트 변수 $Z$를 확률적으로 모델링함으로써 posterior sampling을 통한 탐색이 가능하도록 하여 off-policy 메타러닝에서의 탐색 전략 학습 문제를 해결한다. 메타 학습 시 사용된 off-policy 데이터와 테스트 시점의 on-policy 데이터 간의 분포 차이에 대해서는 인코더를 학습하는 데 사용하는 데이터가 반드시 정책 학습에 사용하는 데이터와 같을 필요는 없다는 점을 이용하여 해결한다.
이 정책은 컨텍스트 $z$의 일부로 볼 수 있으며, 탐색 과정의 확률성은 인코더 $q(z|c)$의 불확실성으로부터 나타난다. actor와 critic은 항상 리플레이 버퍼 $\mathcal{B}$에서 샘플링된 off-policy 데이터로 학습되며, 인코더 학습을 위한 컨텍스트 배치를 샘플링하는 샘플러$\mathcal{S}_c$를 정의한다. 다만 전체 리플레이 버퍼에서 컨텍스트를 샘플링하는 것은 테스트 시점의 on-policy 데이터와의 분포 불일치를 지나치게 심화시켜 성능 저하를 초래한다.
컨텍스트는 반드시 on-policy일 필요는 없다. 우리는 최근 수집된 데이터의 리플레이 버퍼에서 수집하는 전략을 찾아 on-policy 성능을 유지하면서도 학습 효율을 높일 수 있음을 발견했다. 전체 학습 절차는 그림 2와 알고리즘 1에, 메타 테스트는 알고리즘 2에서 확인이 가능하다.



Implementation
우리는 우리의 알고리즘을 soft acto-critic 알고리즘(SAC) 알고리즘을 기반으로 설계했다. SAC는 정책의 엔트로피들의 discounted sum을 구하는 방식으로 동작하며 좋은 샘플 효율성과 안정성을 가진다.
우리는 추론 네트워크 $q(z|c)$, actor $\pi_\theta(a|s,z)$, critic $Q_\theta(s,a,z)$의 파라미터를 공동으로 최적화한다. 이때 샘플링된 latent 변수 $z$를 통해 reparameterization trick을 사용하여 $q_\phi(z|c)$의 파라미터의 경사를 구했다. 추론 네트워크는 critic의 벨만 업데이트로부터의 gradient를 통해 학습된다. 우리는 경험적으로 인코더를 통해 상태-행동 가치 함수를 복원하도록 학습하는 방식이, actor의 반환값을 직접 최대화하거나 상태 및 보상을 복원하도록 학습하는 방식보다 더 우수함을 확인했다.
critic loss는 아래와 같이 사용된다:
$$\mathcal{L}_{\text{critic}} = \underset{\mathbf{z} \sim q_\phi(\mathbf{z} \mid c)}{\mathbb{E}_{(s, a, r, s') \sim \mathcal{B}}} \left[ \left( Q_\theta(\mathbf{s}, \mathbf{a}, \mathbf{z}) - \left( r + \bar{V}(s', \mathbf{z}) \right) \right)^2 \right]$$
- $\bar{V}$ : 목표 네트워크
- $\bar{z}$ : 네트워크를 통해 정의되지 않은 경사
actor loss는 SAR와 비슷하지만 우리는 $z$를 정책 입력에 추가했다:
$$\mathcal{L}_{\text{actor}} = \underset{\mathbf{z} \sim q_\phi(\mathbf{z} \mid c)}{\mathbb{E}_{s\sim \mathcal{B},a \sim \pi_\theta}} \left[D_{KL}\left(\pi_\theta(a|s,\bar{z})\middle\|\frac{\exp(Q_\theta(s,a,\bar{z}))}{Z_\theta(s)}\right) \right]$$
$q_\phi(z|c)$를 추론하기 위해 사용되는 컨텍스트는 actor/critic의 학습에 사용되는 데이터와 분리되어 있다.
- 샘플러 $\mathcal{S}_c$ : 최근 수집된 데이터 배치에서 균등하게 샘플링
- actor & critic : 전체 리플레이 버퍼로부터 균등하게 샘플링된 전이를 통해 학습
Experiments
실험에서 우리는 우리의 방법의 성능을 측정하고 그것의 특성을 분석했다.
- 여러 벤치마크 문제에서 이전 meta-RL과 우리의 방법에 대해 샘플 효율성을 비교
- 확률적 컨텍스트와 사후부포 샘플링이 희소 보상 상황에서 빠른 적응 가능하게 하는지 분석
- ablation 실험을 통해 설계 요소별 기여도 평가
Sample Efficiency and Performance
Experimental setup
우리는 6개의 로보틱 환경에서 MuJoCo 시뮬레이터를 이용하여 PEARL을 평가했다. 메타 강화학습 작업군은 크게 두 종류로 나뉜다:
- 보상 함수의 변화에 대한 적응을 요구 : Half-Cheetah-Fwd-Back, Ant-Fwd-Back, Humanoid-Direc-2D, Half-Cheetah-Vel, Ant-Goal-2d
- 동역학의 변화에 적응애햐 하는 과제 : Walker-2d-Params
이런 meta-RL 벤치마크들은 Finn et al. 과 Rothfuss et al. 에 의해 소개되었다. 모든 작업은 에피소드 200의 길이를 가진다.
우리는 PEARL의 성능을 기존의 정책 경사 기반 meta-RL 방법들과 비교했다:
- ProMP
- MAML-TRPO
- PPO 기반으로 재구현한 RL2
- 모든 알고리즘의 결과는 3개의 무작위 시드에 대해 평균을 냄
또한 우리는 Recurrent DDPG를 본 실험 설정에 맞게 적용하려 시도했으나, 합리적인 성능을 얻는 데에는 실패했다. 적응 데이터의 분포 불일치 문제와 trajectory 기반 학습의 난이도가 복합적으로 작용한 결과로 판단된다.
Recurrent DDPG는 작업 추론을 명시적으로 수행하지 않고 모든 추론과 행동을 RNN이 직접 학습해야 하므로 어려움이 존재한다. 반면, PEARL에서는 작업 추론을 정책과 분리함으로써 off-policy 학습에 적합한 인코더 데이터와 목적 함수를 자유롭게 선택할 수 있는 장점이 있다.
Results
메타 테스트 작업을 평가하기 위해 우리는 trajectory 단위의 적응을 수행했다.
- 첫 번째 trajectory : 사전 분포 $r(z)$에서 샘플링된 컨텍스트 변수 $z$로 수집
- 나머지 trajectories : 인코더를 통해 추론된 $z \sim q(z|c)$로 수집
- 컨텍스트 $c$ : 지금까지 수집된 모든 trajectory를 기반으로 집계
- 최종 테스트 시점의 성능 평가 : 두 개의 trajectory가 컨텍스트에 포함된 이후 수집된 trajectory들의 평균 수익
흥미롭게도 우리는 RL2는 이전 연구들보다 해당 벤치마크에서 더 나은 성능을 보였으며, 이는 PPO 최적화 방식 사용과 더 나은 하이퍼파라미터 선택 덕분일 가능성이 있다.
PEARL은 모든 도메인에서 기존 meta-RL 기법들보다 눈에 띄게 우수한 성능을 보였으며 특히 수렴 이후 성능과 샘플 효율성 모두에서 뛰어남을 보였다. 이는 그림 3에서 확인할 수 있다.

Posterior Sampling For Exploration
우리는 모델에서 사후분포 샘플링이 희소 보상 MDP에서 효율적인 탐색 전략을 가능하게 하는지를 평가했다.
직관적으로 사전 컨텍스트 분포 $r(z)$에서 샘플링하면서 에이전트는 이전에 마주친 훈련 작업의 분포에 기반한 하나의 가설을 선택해 행동을 시작한다. 에이전트가 환경에서 활동하면 컨텍스트 사후분포 $p(z|c)$는 업데이트되며 이를 통해 다양한 가설을 고려하며 점차 실제 작업을 추론하게 된다.
우리는 이를 증명하기 위해 2D 네비게이션 작업을 사용했다.
- 점이 반원 가장자리의 임의 목표 지점으로 이동해야 함
- 훈련에는 목표 100개를 샘플링
- 테스트에는 목표 20개를 샘플링
- 보상은 에이전트가 목표 반경 내에 도달했을 때만 주어짐
- 반경은 0.2 또는 0.8로 설정
- 에피소드 길이는 20 스텝
우리의 목표는 희소 보상을 가진 새로운 작업에 빠르게 적응하는 것이지만 메타 학습 자체를 희소 보상 환경에서 수행하는 것은 매우 어렵다. 따라서 실험에서는 메타 학습 중에 dense reward에 접근 가능한 것으로 가정했다.
이런 설정에서 우리는 MAESN과 PEARL을 비교했다. MAESN은 확률적 task 변수를 모델링하고 on-policy 정책 경사 기반 메타러닝을 수행하는 기존 방법이다.
- PEARL이 더 적은 trajectory만으로도 새로운 희소 보상 목표에 빠르게 적응할 수 있음을 보임
- 샘플 수가 적음에도 불구하고 PEARL이 최종 성능 측면에서도 MAESN을 능가
- 그림 4에서 확인 가능
- PEARL이 더 높은 보상, 더 빠른 적응, 더 높은 효율성을 보임

Ablations
우리는 우리의 접근 방식의 특징을 분석했다.
Inference network architecture
우리는 잠재 컨텍스트 $Z$를 위한 순열 불변 인코더 선택이 적절한지를 평가하기 위해 전통적인 MDP 인코딩 방식인 순환 신경망(RNN) 구조와 비교 실험을 수행했다. PEARL의 다른 특징들은 모두 유지하고 오직 인코더 구조만 변경했다.
RNN은 100 타임스텝에 걸쳐 역전파를 수행했으며 컨텍스트는 PEARL과 달리 full trajectory 단위로 샘플랭했다. 우리는 두 가지 방법으로 actor-critic 배치를 샘플링했다:
- 정렬되지 않은 전이들(PEARL 과 동일)
- trajectory 단위로 묶은 샘플들
그림 5에서 우리는 Half-Cheetah-Vel 도메인에서 메타 훈련 샘플의 개수에 따라 성능을 비교했다. 우리의 인코더를 RNN으로 대체했을 때 PEARL과 유사한 최종 성능을 내지만 최적화 속도가 느려졌고 actor-critic 배치의 trajectory 단위로 샘플링했을 경우 성능이 크게 하락했다. 이 결과는 RL 최적화에서 샘플 간 상관의 중요성을 강조한다.
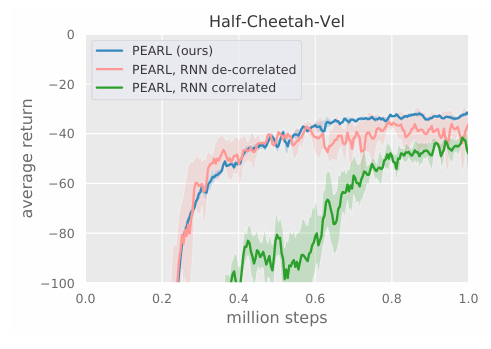
Data sampling strategies
우리의 다음 실험은 훈련 중 사용하는 컨텍스트 샘플링 전략의 영향을 분석했다. PEARL은 기본적으로 샘플러 $\mathcal{S}_c$ 정렬되지 않은 전이들의 배치를 다음 조건으로 샘플링한다:
- 정책에 의해 최근에 수집된 샘플들로 제한되거나
- RL 미니 배치 샘플러에 의해 수집된 전이의 집합에서 분류되거나
우리는 두 가지 옵션을 고려했다:
- 전체 리플레이 버퍼에서 off-policy 데이터를 샘플링, 그러나 RL 배치와는 별도로 구성
- actor-critic 배치와 동일한 데이터를 컨텍스트로도 사용
결과는 그림 6에서 확인할 수 있다. 완전히 off-policy 데이터를 사용하면 성능이 크게 저하되었고 RL 배치와 동일한 데이터를 공유했을 때는 상대적으로 더 나은 성능을 보였다. 이는 데이터 간의 상관관계가 학습을 더 쉽게 만들었기 때문일 수 있다.
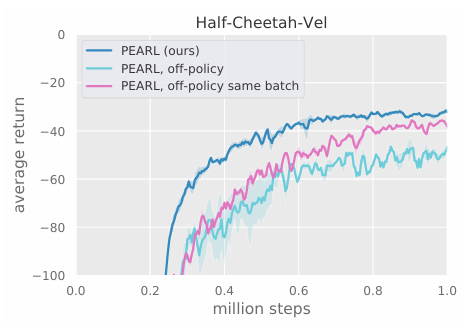
Deterministic context
최종적으로 우리는 확률적으로 잠재 컨텍스트를 모델링하는 것의 중요성을 평가한다. 우리는 확률적 컨텍스트가 희소 보상 설정에서 중요하다고 가정한다. 이는 에이전트가 작업의 분포를 모델링하고 사후 샘플링을 통해 탐색할 수 있도록 해주기 때문이다.
이것을 측정하기 위해 우리는 분포 $q_\phi(z|c)$를 점 추정(point estimate)로 축소한 결정론적 PEARL 버전을 훈련시켰다. 우리는 확률적과 결정론적 버전을 비교했고 그림 7에서 확인이 가능하다.
잠재 컨텍스트 $z$에 확률성이 없으면 정책에서만 확률성이 발생하고 이 확률성은 시간에 따라 변화하지 않기 때문에 시간적으로 확장된 탐색이 어려워진다. 그 결과, 이 결정론적 접근은 희소 보상 네비게이션 작업을 해결하지 못했다.

Conclusion
우리는 새로운 작업에 적응하기 위해 정책이 조건화되는 잠재 컨텍스트 변수에 대한 추론을 수행하는 새로운 meta-RL 알고리즘인 PEARL을 제안한다. 우리의 접근 방식은 작업을 추론하는 문제와 푸는 문제를 분리함으로써, off-policy 강화학습 알고리즘을 메타 학습에 자연스럽게 결합할 수 있도록 설계했다. 잠재 컨텍스트를 확률적으로 모델링함으로써, 테스트 시점에서 posterior sampling 기반의 탐색이 가능해지고 이는 시간적으로 확장된 행동으로 이어져 적응 효율성을 향상시킨다. 우리의 방법은 다른 meta-RL과 비교하여 더 나은 성능을 보였다.
https://proceedings.mlr.press/v97/rakelly19a
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
Deep reinforcement learning algorithms require large amounts of experience to learn an individual task. While meta-reinforcement learning (meta-RL) algorithms can enable agents to learn new skills ...
proceedings.mlr.press