[논문 정리] Combining Induction and Transduction For Abstract Reasoning
Introduction
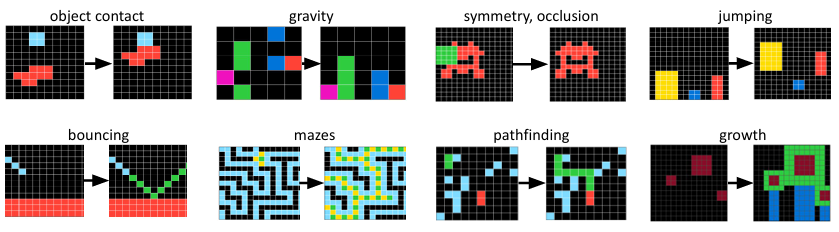
적은 예시로부터 강력한 일반화를 적용하는 것은 AI가 사람같은 지능을 가지기 위해서 가장 중요한 길이다. 많은 최근 연구들이 이러한 일반화를 추상적 추론의 형태로 보고 있으며, 입력-출력과 테스트 입력을 받았을 때 올바른 테스트 출력을 예측하는 전략을 사용하고 있다. analogical reasoning이나 chain-of-thought, inductive program synthesis, transductivve prediction과 같은 방식들이다. Abstraction and Reasoning Corpus, 줄여서 ARC는 적은 예시만으로 새로운 능력을 획득할 수 있는 능력을 평가하는 지표이다. 각 ARC 문제는 색깔의 그리드가 있는 입력-출력 쌍이 주어지고 길찾기, 충돌, 대칭, 중력, 튕기기, 세기 등의 다양한 추론능력을 요구한다. 그림 1에서 예시를 확인할 수 있다.
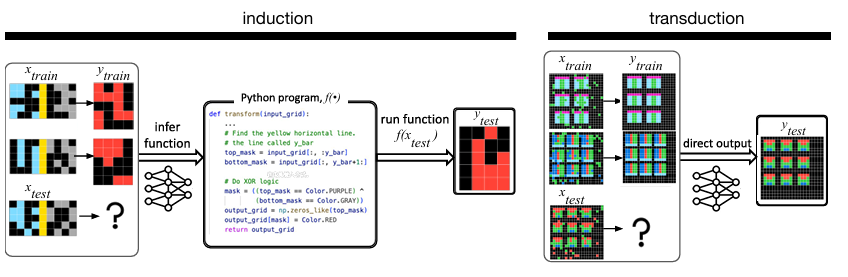
우리는 ARC 문제를 해결하기 위해 induction과 transduction을 신경망 기반 접근 방식을 연구했다. Induction은 $f(x_\text{train}) \approx y_\text{train}$을 만족하는 함수 $f$를 찾고 그 함수를 $y_\text{test} = f(x_\text{test})$에 적용하는 방식이다. Transduction은 출력 $y_\text{test}$를 함수 $f$ 없이 생성하는 것이다. 직관적으로 induction은 푸는 사람에게 학습 데이터를 설명할 수 있는 가설을 세우고 그것을 통해 예측을 만드는 것이다. Inductive 학습자들은 더 많은 시간을 더 좋은 가설을 위해 쏟을 수록 더 좋은 정답률을 나타낸다. Transduction은 훈련 예제 자체가 새로운 예측을 생성하는 데 직접적인 역할을 해야하며 성공적인 예측을 위해 명시적인 설명이 필요하지 않다. 그림 2에는 해당 예시가 나타난다.
우리는 induction과 transduction을 위한 신경망을 학습시키기 위해 대규모의 합성 문제 집합을 생성했다. 거기서 우리는 induction과 transduction을 위한 신경망 모델이 서로 강하게 보완적이라는 사실을 발견했다. 두 모델은 일반적으로 서로 다른 문제를 해결하는 것은 서로 다른 선행 변수, 데이터, 또는 아키텍처 때문으로 설명된다. 그러나 동일하게 통제한 상황에서도 induction에 의해 해결되는 것들은 transduction에 의해 해결되지 않았고 반대도 마찬가지였다. 게다가 induction과 transduction은 쉽게 앙상블 될 수 있다. 이런 보완성은 실제 응용에서 유용한 시사점을 제공한다.
본 연구는 프로그램 합성과 관련이 깊다. 우리는 함수 $f$를 파이썬 코드로 표현했고 이것은 induction 합성 프로그램을 의미한다. 우리는 transduction 모델을 파이썬 스크립트로 구성된 LLM에 학습시켰고 이것은 transduction이 입력-출력의 상징적 코드로 학습된다는 것을 의미한다. 프로그램 학습이 범용 AI를 만드는 유망한 관점이었지만 지배적인 이론은 신경망이 코드를 모방하는 것이 아닌 명시적인 코드 생성이이다.
이 신경망을 테스트하는 것은 대규모의 함수-학습 문제들이 필요하다. 새로운 함수를 만드는 것 뿐만 아니라 거기에 적합한 좋은 입력까지 생성해야 하기에 굉장히 어려운 문제다. 그림 1에 나타난 변환들을 고려하면 어떤 함수에는 좋은 입력이 다른 함수에서는 적절하지 않을 수 있다. 이를 해결하기 위해 우리의 데이터 생성기는 파이썬 함수 $f$를 생성하고 $f$에 대한 입력을 샘플링하기 위한 확률적 프로그램을 생성한다. 그 후 이 프로그램들을 실행하여 입력-출력 쌍을 생성한다. 이런 방식은 해당 변환 함수에 적합한 입력을 생성하는데 도움을 주며 동시에 $x_\text{train}$과 $y_\text{train}$이 결정론적인 매핑에 의해 설명 가능하도록 제약을 건다.
우리의 기여는 아래와 같다:
- induction과 transduction을 위한 신경망 모델이 서로 보완적이라는 것을 발견했다.
- 100-160개의 파이썬 솔루션으로 자동 데이터 생성 방법을 만들고 확장하여 400k의 새로운 문제와 파이썬 솔루션 쌍을 생성하는 데이터 생성 파이프라인을 제안했다.
- 수작업 라벨 데이터를 늘릴 경우 성능이 빠르게 한계에 도달하지만 연산량을 늘리면 성능이 지속적으로 향상되는 것을 발견했다.
- 각 방법에 의해 해결되는 문제들을 분석하고 사람의 문제 해결 방식과 비교했다.
Neural Models For Induction And Transduction
우리는 입력 공간 $\mathcal{X}$의 항목을 출력 공간 $\mathcal{Y}$에 매핑하도록 훈련받는 few-shot 지도학습 문제를 다룬다. K-shot 학습에서 우리는 K개의 훈련 입력-출력 쌍을 받아 결과를 예측하는 것이 목표다. 우리가 사용하는 K-shot 학습 모델은 메타러닝을 통해 학습되며 이 과정에서 정답 함수가 주어져 induction 모델을 감독하는 역할을 한다.
Definition: Neural networks for induction and transduction
transduction을 위한 신경망은 $(x_\text{train}, y_\text{train}, x_\text{test})$를 받아 $y_\text{test}$에 대한 확률 분포를 출력하는 함수 $t$이며 파라미터 $\theta$를 이용해 학습한다.
$$t_\theta : \mathcal{X}^K \times \mathcal{Y}^k \times \mathcal{X} \to \Delta(\mathcal{Y})$$
여기서 $\Delta(S)$는 집합 $S$위의 확률 분포들의 집합을 의미한다.
induction을 위한 신경망은 $(x_\text{train}, y_\text{train}, x_\text{test})$를 받아 $\mathcal{X}$를 $\mathcal{Y}$에 매핑하는 함수 $f$에 대한 확률 분포를 출력하는 함수 $i$이며 마찬가지로 학습 가능한 파라미터 $\theta$를 가진다.
$$i_\theta : \mathcal{X}^K \times \mathcal{Y}^k \times \mathcal{X} \to \Delta(\mathcal{X} \to \mathcal{Y})$$
Training induction and transduction
두 모델은 모두 메타러닝을 통해 학습되었다. 우리는 각 문제에 대해 ground-truth 함수 $f$가 주어진 few-shot 학습 문제들의 메타러닝 데이터셋 $\mathcal{D}$를 가정하며 이 함수 $f$는 모든 $(x, y) \in (x_\text{train},y_\text{train})$ 및 $ (x_\text{test},y_\text{test})$에 대해 $f(x) = y$를 만족한다. Inductive and transductive 모델은 아래의 loss 함수를 통해 메타 학습된다.
$$\text{TRANSDUCTION LOSS} = \mathbb{E}_{(x_\text{train},y_\text{train},x_\text{test},f)\sim\mathcal{D}}[-\log t_\theta(y_\text{test}\mid x_\text{train},y_\text{train},x_\text{test})]$$
$$\text{INDUCTION LOSS} = \mathbb{E}_{(x_\text{train},y_\text{train},x_\text{test},f)\sim\mathcal{D}}[-\log i_\theta(y_\text{test}\mid x_\text{train},y_\text{train},x_\text{test})]$$
Testing induction and transduction
메타러닝을 진행한 후 모델은 테스트 시점의 few-shot 학습 문제 $(x_\text{train},y_\text{train},x_\text{test})$에 직면한다. Transductive 모델은 $y_\text{test}$에 대한 가장 가능성 높은 출력을 예측하며 이는 beam search로 근사된다. 반면 Inductive 모델은 테스트 시점의 budget $B$만큼 함수 $f_1,\dots,f_B$를 샘플링하고 이 함수들이 $(x_\text{train},y_\text{train})$를잘 설명하는지를 기준으로 필터링한 후 최종적으로 예측을 수행한다.
$$
\begin{aligned}
\text{Transduction:} \quad &\hat{y}_{\text{test}} =
\mathop{\arg\max}_{y \in \mathcal{Y}}\, t_\theta(y \mid x_{\text{train}}, \mathbf{y}_{\text{train}}, x_{\text{test}}) \\
\\
\text{Induction:} \quad &\hat{y}_{\text{test}} \sim \text{Uniform}(\mathcal{F}) \\
&\quad\text{where } \mathcal{F} = \left\{ f_b(x_{\text{test}})\ :\ 1 \le b \le B \text{ if } f_b(x_{\text{train}}) = \mathbf{y}_{\text{train}} \right\} \\
&\quad f_b \sim i_\theta(f \mid x_{\text{train}}, \mathbf{y}_{\text{train}}, x_{\text{test}})
\end{aligned}
$$
Combining induction and transduction
Induction은 훈련 예시에 맞춰 가설 후보들이 맞는지 검증할 수 있는 장점이 있다. 솔루션을 찾았을 때, 그것이 타당한 해답인지 판단할 수 있다. 그러나 가끔씩 아무 솔루션도 찾지 못하는 경우가 있다. Transduction은 반대의 성향을 가진다. 우리는 예측이 예시 문제와 맞는지 확인할 수 없지만 그럼에도 정답 후보는 제공한다. 우리는 앙상블하여 먼저 induction을 적용하고 후보가 없을 경우 transduction을 이용하여 후보 가설을 만든다.
$$\begin{aligned}
\text{Ensemble:} \quad &\hat{y}_{\text{test}} \sim \text{Uniform}(\mathcal{F}) \quad \text{if } \mathcal{F} \ne \emptyset \\
&\mathop{\hat{y}_{\text{test}} = \arg\max}_{y \in \mathcal{Y}}\, t_\theta(y \mid x_{\text{train}}, \mathbf{y}_{\text{train}}, x_{\text{test}}) \quad \text{if } \mathcal{F} = \emptyset
\end{aligned}$$
Instantiating the framework for ARC
$\mathcal{X}$의 모든 입력과 $\mathcal{Y}$의 모든 출력은 2D 그리드로 1-30 픽셀 사이로 이뤄져 있으며 각 픽셀은 10개 중 하나의 색깔을 포함하고 있다. ARC 문제는 대부분 추상적인 프로그램 구조를 가지고 있기 때문에 함수 $f$를 보편적인 계산 능력을 가진 파이썬 코드로 작성했다. induction 모델은 파이썬 코드를 생성해야 하며 우리는 소스코드에 대한 사전학습이 되어 있는 Llama3.1-8B-instruct를 초기 모델로 사용한다. 2D 색상 그리드는 픽셀 하나당 하나의 토큰으로 문자열로 변환된다. 이후 우리는 모델을 induction 및 transduction 작업에 맞게 메타러닝 방식으로 fine-tuning한다.
Generating Datasets For Induction And Transduction
ARC 문제 안에는 다양한 종류의 콘셉트가 들어 있기 때문에 ARC 스타일의 문제를 생성하는 것은 어려운 일이다. 함수뿐 아니라 함수에 대한 좋은 예시를 만들어야 하는 것 또한 어려운 문제다.
고수준에서 보면, 우리의 데이터셋은 100개의 수작업으로 작성된 파이썬 프로그램들로부터 출발한다. 각 프로그램은 ARC 스타일 문제 하나를 해결하는 함수이며, 동시에 해당 함수에 적절한 입력 그리드를 무작위로 생성하는 기능도 포함한다. 우리는 이것을 seeds라고 부르며 각 seed는 자연어 주석을 포함하고 있다. 그리고 우리는 이것을 LLM에 이용하여 seed와 결합하고 수천개의 프로그램을 생성한다. 그림 3에서 확인 가능하다.

각 시드는 3가지 부분을 포함하고 있다:
- ARC 문제에 대한 구체적인 자연어 표현(문제를 해결하는 방법), Python 주석 형태
- 파이썬 함수 transfrom_grid : input을 output으로 매핑해주는 함수 $f$에 해당
- 파이썬 함수 generate_input : 무작위로 새로운 입력을 생성(생성된 것은 transform_grid에 입력으로 들어감)
Prior knowledge
각 seed는 훈련 작업을 해결하는 좋은 프로그램 예시를 보여주며 이를 통해 시스템에 사전 지식을 전달한다. 우리는 이런 지식 중 공통적으로 유용한 부분을 추려서 Python 라이브러리 형태로 정리했고 거기에는 무작위 스프라이트 생성, 대칭 탐지, 객체 추출과 같은 함수들이 포함된다.
그러나 이런 사전 지식은 ARC를 위한 Domain Specific Language와는 다르다. DSL은 도메인 특화된 기본 연산들을 정형화된 조합만 허용하여 프로그램의 범위를 제한한다. 반면, 우리는 임의의 파이썬 코드를 허용했고 ARC의 매우 다양한 문제들까지 포괄할 수 있다.
Remixing the seeds
합성 데이터를 만들기 위해 우리는 LLM을 이용하여 seed들을 "remix" 했다. 새로운 합성된 ARC 문제가 생성되는 것은 3가지 과정으로 나뉘며 그림 11에서 확인 가능하다:
- 기존 seed들의 자연어 설명을 LLM에 in-context learning 방식으로 프롬프트하여 여러 문제의 구성 요소를 재조합하거나 변형한 새로운 설명을 샘플링한다.
- 생성된 자연어 설명을 기반으로 Retrieval Augmented Generation을 이용하여 코드를 생성한다. RAG 파이프라인은 비슷한 표현을 가진 seed를 검색하고 LLM에 프롬프트하여 새로운 표현을 위한 코드를 생성한다.
- 새로 생성된 generate_input 함수를 실행해 입력 그리드를 만들고 이를 transform_grid에 통과시켜 최종 입력-출력 쌍을 생성한다.
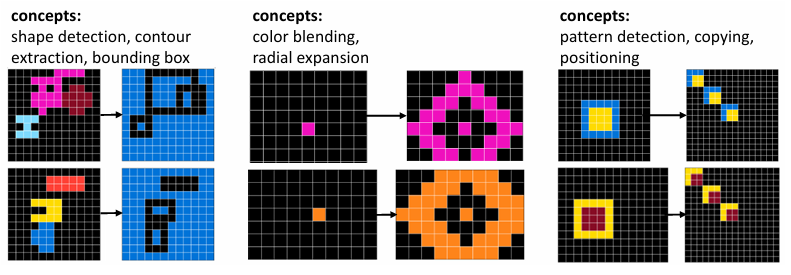
그림 4는 파이프라인을 통해 생성된 예시 문제들을 보여준다.
Empirical Study Of Induction And Transduction
우리는 inductive 모델과 transductive 모델을 3가지의 목표를 이루기 위해 훈련했다:
- 두 접근 방식이 어떻게 성능 면에서 비교되는지
- 학습에 투입한 시간/노력에 따라 성능이 어떻게 스케일링되는지
- 테스트 시점의 연산 자원을 늘릴 때 성능이 어떻게 향상되는지(단, 이 항목은 induction 모델에만)
이 실험에서의 성능은 ARC의 공개 validation split에 포함된 400개의 문제를 기준으로 평가되며, 이 문제들은 훈련 split보다 더 어렵다. 이번 파트에서 설명할 시스템은 우리가 직접 seed를 만든 100개의 문제만을 사용하여 학습되었다.
Induction and Transduction are strongly complementary
똑같은 문제에서 학습을 진행했음에도 inductive 모델과 transductive 모델은 서로 다른 작업을 해결했으며, 어느 한쪽이 압도적으로 더 효과적인 것도 아니었다. 둘은 비슷한 해결률을 보이지만 induction에 의해 풀린 문제의 대부분은 transduction 모델은 풀지 못했다. 그림 5A에 푼 문제의 개수를 확인 할 수 있다.
결과에 대한 대안적인 설명은 다음과 같다. "induction과 transduction이 실제로 보완적인 것이 아니라 서로 다른 랜덤 초기화로 학습된 두 모델이 우연히 다른 문제를 푼 것은 아닐까?" 이것을 검증하기 위해 우리는 여러 개의 모델을 각각 다른 무작위로 초기화시켜 여러 번 훈련을 진행했다. 그 결과 해결한 문제들은 반복 실험 간에도 안정적으로 유지되었으며, 이는 induction/transduction이 특정 유형의 문제에 지속적으로 강점을 가진다는 것을 의미한다.(그림 5B 참고). 즉, 어떤 문제는 induction과 가깝고 어떤 문제는 transduction과 가까운 것이다(그림 6참고).


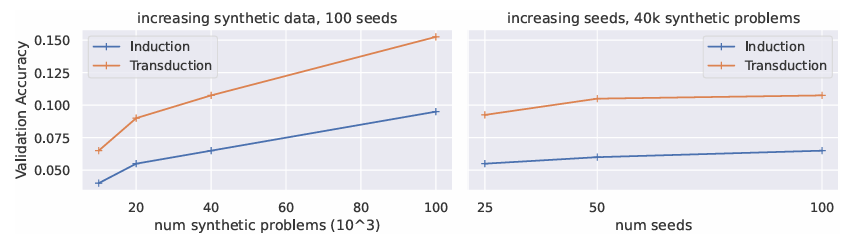
Performance scales with dataset size, but quickly saturates with increasing number of seeds
우리는 모델을 훈련할 때, 사람이 만든 seed의 개수와 그 seed로부터 만들어진 데이터의 양을 조절하며 실험을 진행했다. 실험 그래프는 그림 7에서 확인할 수 있다. fine-tuning을 위한 합성 데이터 양이 증가할수록 성능이 향상되었지만 사람이 만든 seed의 수가 늘어나도 성능은 크게 개선되지 않았다. 우리는 이것이 각 seed가 핵심 개념을 포함하고 있기 때문이라고 생각한다. 이것은 일정량의 seed가 존재한다면 사람의 데이터 라벨링 없이도 데이터의 생성량을 늘릴 수 있다는 것이다. 나아가 ARC를 넘어서 우리의 방식이 다른 few-shot 함수에도 사용될 수 있다는 것을 의미한다.
Induction performance scales with test-time compute
우리는 induction 모델의 테스트 시점 샘플링 예산을 늘리면서 테스트를 진행했다. 그림 8의 왼쪽에서 확인 가능하다. 그 결과 샘플 수가 증가할수록 정답률이 거의 단조 증가하는 경향을 보였다. 이론적으로는 샘플을 더 많이 생성할수록 훈련 예시에는 맞지만 테스트 출력은 틀린 false-positive 솔루션이 나올 가능성이 커진다. 실제로 훈련 예시에 맞는 샘플들 중 약 9%가 false-positive였다. 하지만 그림 8의 오른쪽에 따르면 이 9% 중 절반의 경우 모델은 여전히 정답 출력에 가장 높은 확률 질량을 할당하고 있었다. 즉, 단순한 다수결 방식만 사용해도 이러한 false-positive 들을 걸러낼 수 있다.
Stronger LLMs make better synthetic data, and induction is more sensitive to data quality
비용을 줄이기 위해 앞선 실험들에서는 모두 GPT4o-mini를 사용해 synthetic 데이터를 생성했다. 하지만 더 강력한 LLM을 사용했을 때 데이터 품질이 성능에 어떤 영향을 주는지를 분석하기 위해, 우리는 GPT-4를 이용해 자연어 문제 설명만 생성하고 코드 생성은 여전히 GPT4o-mini가 수행하는 방식으로 합성 문제를 생성했다. induction 모델에서는 성능을 크게 향상시켰지만 transduction 모델은 데이터 품질 변화에 비교적 둔감했다(표 1 참조).

Scaling our Method
우리가 발견한 사실에 영감을 받아 2가지의 더 큰 데이터셋을 만들어 우리의 방식을 확장했다:
- ARC-Heavy: 200k problems from 160 seeds. ARC-Heavy의 목적은 우리의 방식이 복원하기 쉽도록 확장하고 기존 훈련 데이터셋에서 성능이 부족했던 영역을 보완하는 것이다. 우리는 위에서 사용한 모델들을 훈련 데이터에 적용한 후, 성능이 낮은 60개의 문제를 찾아 그 문제들을 위한 새로운 seed 60개를 추가했다. 이 seed들로부터 우리는 200k의 synthetic 문제를 만들었고 위와 마찬가지로 GPT4가 자연어를 만들고 GPT4o-mini가 파이썬 코드를 생성했다.
- ARC-Potpourri: 400k problems from heterogeneous sources. ARC-Potpourri의 목적은 가능한 최대한 큰 규모의 데이터셋을 구축하는 것이다. 데이터 출처의 일관성이 없어도 괜찮다는 전제가 깔려있다. 이 데이터셋은 ARC-Heavy 전체를 포함하며 여기에 위에서 사용된 모든 합성 데이터를 추가하고, 마지막으로 ReARC에서 제공한 transduction 전용 학습 예제 10만개를 추가했다.
Test-time improvements
우리는 transduction 모델을 test-time training과 reranking 스키마를 이용하여 개선했다. reranking 스키마는 하나의 문제를 여러 방식으로 augmentation한 후, 각 augmentation에 대해 예측된 출력들 중에서 가장 가능성이 높은 결과를 종합적으로 선택하는 방식이다. 또한 우리는 test-time에서의 샘플링 예산을 2만 개 프로그램까지 확장했다.
우리는 개선한 시스템을 BARC라고 부른다. 표 2는 BARC 모델들의 성능을 보여준다. transduction 과 induction은 모두 효율적이고 induction이 test-time training/reranking 전에는 조금 더 많은 문제를 해결했다. 적용 후에는 비슷한 결과를 보였다. 앙상블 점수는 56.75%로 전에 기록한 점수를 넘겼다. 이후 Akyurek et al.더 나은 test time training을 이용하여 우리 모델의 성능을 61.9%까지 늘렸다. 반면 우리의 모델 없이 test-time training만으로 학습한 경우에는 성능이 오히려 떨어졌으며 이는 정교한 test-time training만으로는 program synthesis의 역할을 완전히 대체할 수 없음을 시사한다.
Scaling down our method
우리의 플래그쉽 모델은 너무 비싸서 Kaggle의 private test에서는 돌릴 수가 없었다. 그렇기에 우리는 크기를 줄여 test-time training을 생략하고 오직 336개의 프로그램만을 샘플링하고 transduction의 빔 사이즈를 3으로 줄였다. 이 점수는 Kaggle에서 19%, validation set에서는 36.5%를 달성했다. 표 3에서 나타나듯 탐색 예산이 줄어들면 프로그램 합성의 효과가 크게 감소하는 것을 확인할 수 있었다.

Which Problems Are Easier For The Models, And For Humans?
Do problems that challenge humans also challenge the model, and vice-versa?
우리는 ARC validation problem을 LeGris의 기준에 따라 5개의 난이도 클래스로 분류했다. 그림 9는 사람과 모델의 정확도의 관계를 보여준다. 모든 모델은 어려운 문제에서 사람의 성능을 넘었지만 쉬운 문제에서는 더 낮은 성능을 보였다. 그 이유는 우리의 모델이 단순한 파이썬 프로그램에서 학습되었기 때문이며, 이는 어떤 문제들이 코드로 표현했을 때 단순하며 트랜스포머로부터 학습하기 쉽지만 사람에게는 굉장히 어렵다는 것이다. 반대로 사람은 prior 지식을 통해 모델이 일반화하기 어려운 문제도 쉽게 푼다는 것을 시사한다. 다양한 난이도의 문제들에 대해 transduction 과 induction은 보완적인 역할을 수행했다.
Which concepts are easier for the models?
우리는 ConceptARC라는 ARC의 대안 벤치마크에서 모델을 평가했다. ConceptARC는 각 문제를 "sameness", "above vs below" 등과 같은 단일 고수준 개념 기반의 개념 그룹으로 분류하여 구성된다. 우리는 ARC-Potpourri에 훈련에 사용된 모델을 사용했고 induction과 transduction이 쉽게 푸는 문제의 카테고리를 발견했다. 예를 들어 세기 같은 개념은 symbolic한 코드를 통해 잘 풀렸고 반면 형태가 수평적인지 수직적인지 판단하는 것과 같은 지각적 개념들은 transduction이 더 우수한 성능을 보였다.
ConceptARC는 transduction과 induction의 근본적인 차이를 또 다른 차원에서 보여준다. ConceptARC는 여러 개념의 조합이 아닌 하나의 명확한 개념만을 포함하므로 symbolic 구성에 강점을 지닌 induction 모델의 장점이 사라지게 된다. 반대로 transduction은 symbolic한 구조는 없지만 각 개별 개념을 subsymbolic 방식으로 유연하게 처리할 수 있기 때문에 ConceptARC와 같은 단일 개념 문제에서 상대적인 강점을 보일 수 있다.
Discussion
What we learn about robust sample-efficient generalization
명시적인 상징적 가설이나 암묵적인 신경 표현만으로는 모든 문제를 해결할 수 없다 : 각자 그들만의 도메인이 존재하며 단순히 앙상블 모델은 모든 문제를 해결할 수 없다. 더 영리한 neural program search를 설계하거나 더 많은 데이터로 예측하는 것은 좋은 결과를 보이지 못할 것이다. 대신 우리는 신경적 혹은 상징적 형태로 환원할 수 없는 표현이 필요하며, inductive와 transductive 추론이 깊게 얽힌 형태가 필요하다. 여기서 하나의 아이디어는 상징적이지 않은 언어를 사용하여 프로그램 합성을 진행하는 것이며 핵심 지식을 이용하여 사전 학습시키는 것이다.
To what extent is this methodology applicable beyond ARC?
우리가 제시한 접근법이 ARC 외의 문제에 얼마나 적용 가능한지에 대해 중요한 논의를 던진다. Few-shot function learning이라는 프레임워크 자체는 범용적이지만 우리가 제안한 방식은 symbolic 코드로 일반화를 기술할 수 있는 문제에 가장 적합하다. 하지만 이러한 형태의 프로그램은 LLM의 사전 학습 데이터에 흔히 등장하지 않기 때문에, 단순히 프롬프트 기반으로는 좋은 성능을 기대하기 어렵다. 대신, 이번 연구에서처럼 약 100개 수준의 seed를 인위적으로 구성하고, 이를 기반으로 학습하는 것이 보다 현실적인 전략이다.
Theroretically, induction and transduction should not be so complementary
이론적으로는 induction과 transduction이 그렇게까지 서로 보완적일 이유가 없다. 예를 들어, 커널 트릭처럼 induction 문제를 transductive하게 바꾸는 방법도 존재하고, transformer가 universal approximator라는 점을 고려하면, 충분한 meta-training 데이터가 주어진다면 두 방식 모두 유사한 성능에 수렴할 것으로 기대된다. 하지만 실험 결과에서는 여전히 두 접근 방식 사이에 성능 차이가 존재했다. 이는 오히려 이론적 기대와 어긋나는 흥미로운 결과다. 즉, 실제 세계에서는 induction과 transduction이 서로 다른 inductive bias를 갖고 있고, 학습 데이터 구조나 문제 특성에 따라 각기 다른 방식으로 문제를 해결하게 된다는 것이다.
Are we cheating by training on 400k synthetic problems?
ARC의 기본 정신은 소수의 예시로부터 일반화하는 능력을 시험하는 것이다. 그런데 이번 연구에서는 400k개의 합성 문제로 모델을 학습시켰기에 이는 ARC의 철학에 어긋나 보일 수 있다. 그러나 이 중 진짜 학습 데이터는 160개의 seed이며 나머지는 그것을 기반으로 생성된 dream data에 가깝다. 그렇기에 이번 연구는 샘플 효율은 높지만 계산 효율은 낮은 방법이라고 평가할 수 있다.
Impact on ARC efforts
우리의 코드와 데이터는 ARC 커뮤니티에도 영향을 미쳤다. 대표적으로 Akyurek et al.은 이 자료를 바탕으로 첫 번째 open-source 인간 평균 수준의 성능을 갖춘 시스템을 구현했고 ARC 2024대회 2등 팀 역시 이 데이터를 활용해 성과를 낸 것으로 보고되었다. 다른 유효한 방법이 존재함을 증명하고자 했고 실제로 그러한 가능성을 보여주었다.
From domain-specific languages to domain-specific libraries
기존 program synthesis 연구들은 DSL을 설계하는 데 집중해왔다. 그러나 본 연구에서는 python 같은 범용 언어를 기반으로 하고 그 위에 도메인 특화된 라이브러리를 얹는 방식을 사용했다. 그리고 이러한 방식이 훨씬 유연하고 표현 영역을 훨씬 넓게 확보할 수 있다고 주장한다.
How to represent input-output mappings
우리의 seed는 다음과 같은 구조를 따른다:
- 입력 그리드를 출력으로 변환하는 시스템
- 다양한 입력을 생성하는 함수
- 위 두 함수에 대한 자연어 설명
이 구조는 단순히 input-output 예제를 생성할 수 있게 해줄 뿐만 아니라 자연어 기반 remix가 가능하도록 하는 기반이 되며 문제 그 자체의 설명이 latent하게 남아 있는 형태로서도 기능한다.
Next steps suggested by biological intelligence & wake-sleep
본 연구는 심리학에서 제안된 system1과 system2 모델과도 연결 가능하다. 현재 모델 구조는 두 시스템 중 하나만 사용한다. 인간은 둘 다 사용하여 순환적 사고 구조를 가지는데 우리는 induction과 transduction을 더 깊게 통합하는 방식이 자연스러운 다음 단계라고 제안한다.
이 방법은 wake-sleep 학습 구조로도 해석될 수 있다. 여기서 prompt + seed는 생성모델이고 fine-tuned 모델은 추론 모델이다. 이 구조에 기반해 다음과 같은 확장이 가능하다:
- 최근 풀린 test 문제를 기반으로 새로운 synthetic 문제를 생성하는 dreaming 단계
- ARC 라이브러리를 자동으로 확장하거나 새로운 neural primitive를 추가하는 library learning
Limitations
이 시스템은 새로운 문제를 풀면서 스스로 성장하지 않는다. 모델은 few-shot learner처럼 작동하지만 그 역량은 수작업 seed에 encode된 정보에 전적으로 의존한다. ARC 외의 벤치마크에서 검증되지는 않았지만 ARC 자체가 복잡하고 개방적인 문제들로 구성되어 있기 때문에 하나의 중심 실험 환경으로는 여전히 유효하다고 본다.
https://arxiv.org/abs/2411.02272
Combining Induction and Transduction for Abstract Reasoning
When learning an input-output mapping from very few examples, is it better to first infer a latent function that explains the examples, or is it better to directly predict new test outputs, e.g. using a neural network? We study this question on ARC by trai
arxiv.org