Why This Paper?
music generation의 배경지식을 쌓기 위해 리뷰 논문을 위주로 찾아보기로 결정했다. 첫 번째로 읽을 논문이 이것이다.
Introduction
인공지능의 발전과 함께 음악은 자동화된 창작에 대한 높은 역량과 잠재력을 가진 것으로 입증되었다. 지능형 음악 생성(intelligent music generation)은 자동 작곡 문제를 해결하는데 전념하며, 현재 컴퓨터 창의성 분야에서 가장 생산적인 하위 분야로 자리 잡고 있다.
기호적 음악 생성(symbolic music generation)은 음악을 기호의 연속(sequence of symbols)으로 표현한 후, 특징 학습(feature learning)과 생성 모델링(generative modeling)을 수행하는 방식이다. 여기서 2가지 핵심 속성은 구조적 인식(structural awareness)과 해석 능력(interpretive ability)이다.
- 구조적 인식(structural awareness) : 장기적 의존성을 포함하여 자연스럽게 일관성 있는 음악을 생성
- 해석 능력(interpretive ability) : 복잡한 계산 모델을 사용자가 제어할 수 있는 인터페이스로 변환
이 분야는 작곡가들이 기존의 음악을 발전시키거나 새롭게 음악을 창작하는 등 다양한 목적에 사용이 가능하다.
AI 작곡 시스템은 Music Generation System(MGS)라고 불린다. 제작에는 (1) 작곡, (2) 편곡, (3) 사운드 디자인, (4) 믹싱, (5) 마스터링의 5단계가 존재한다. 본 연구는 주로 작곡과 편곡에 중점을 두며 기호의 연속(sequence of symbols)으로 음악 아이디어를 변환하는 과정에 대해 다룬다.
생성된 음악은 다양한 악기를 포함할 수 있으며 베이스, 드럼, 기타, 피아노, 바이올린, 현악기, 관악기 등의 연구와 응용이 활발히 진행되고 있다. 그러나 민속 악기 음악 생성에는 여전히 한계가 존재하며 추가 연구가 필요하다.
현재 음악 생성 시스템에 관한 리뷰 논문들이 여럿 존재하지만 대부분 한계가 존재한다. 일부 논문에서는 알고리즘과 모델에 대한 충분한 분석이 부족하고, 다른 연구들은 미래 전망을 전통적이고 보수적인 관점에서 다루고 있으며, Plug et al은 음악 생성의 일반적인 방법론에 대한 정보 제공이 부족했다.
기존 리뷰 논문의 한계를 고려하여 본 연구에서는 음악 생성의 다양한 하위 연구 방향에 대한 최신 논문을 포괄적으로 분석하고 각 연구의 강점과 약점을 지적하며 생성 방법에 따라 명확하게 분류하여 정리한다. 그리고 음악의 디지털적 특성을 잘 이해하기 위해 정보 흐름(information stream)으로 표현하는 2가지 주요 방식과 음악 생성 평가에 자주 사용되는 데이터셋을 소개한다. 마지막으로 음악 생성 기술의 향후 발전 방향을 전망하며 마무리할 예정이다.
Overview
음악의 가장 기본적인 요소에는 음의 높이(pitch), 길이(length), 강도(strength), 음색(timbre)가 포함된다. 이러한 기본 요소들이 결합하여 멜로디(melody), 화성(harmony), 리듬(rhythm), 톤(tone)을 형성한다. AI 작곡에서 멜로디는 자동 음악 생성 시스템의 주요 목표를 구성한다. 대부분의 경우 특정 스타일과 유사한 멜로디를 생성하는 것을 목표로 한다.
화성도 자동 음악 생성에서 중요한 요소이며 목표 스타일과의 유사성에 의해 결정되는 경우가 많다. 합창 화성(choral harmony)에서는 음의 이동 원칙(sound guiding principles)을 따르는 것이 유사성을 판단하는 기준이 되며 대중 음악(popular music)에서는 화성 진행(chord progression)이 주로 멜로디를 보조하는 역할을 한다.
오디오 생성(audio generation)과 스타일 변환(style conversion)도 지능형 작곡(intelligent composition) 분야에서 인기 있는 연구 방향이다. 특정 음악 생성 시스템의 전체 구조는 그림 1에 나와있다. 한편, 과거의 많은 음악 생성 시스템은 딥 뉴럴 네트워크(deep neural networks)나 진화 알고리즘(evolutionary algorithms)을 포함하지 않았으며 규칙적 제약만을 기반으로 출력을 생성했다.
음악을 생성하는 과정에서 음악 콘텐츠는 디지털 형태로 인코딩되어 알고리즘의 입력으로 제공되며, 지능형 알고리즘이 학습 및 훈련을 거쳐 멜로디, 코드, 오디오, 스타일 변환 등 다양한 유형의 음악적 요소를 출력한다. 음악은 시간적 흐름에서 계층적 구조(hierarchical structure)를 가지며 동기(motive) => 악구(phrase) => 악절(segment)로 구성된다. 그림 2를 보면 음악의 전체적인 구조는 반복과 변형이 결합되어 주제(theme), 리듬(rhythm), 감정(emotion)을 형성한다.
음악은 일반적으로 여러 개의 성부(voice parts)로 구성되는데 각 성부는 동일하거나 다른 악기일 수 있다. 그리고 개별 성부는 완전한 구조를 가지면서 전체적으로 조화를 이루어야 한다. 이러한 제약 조건을 고려했을 때 음악 생성은 여전히 매우 도전적인 문제로 남아 있다.


Representation
음악은 다양한 수준의 추상화에서 감정을 전달하는 정보 흐름으로 볼 수 있다. 생성 시스템(generative system)의 입력은 일반적으로 음악의 특정 표현 방식이며, 이 방식은 시스템의 입력 및 출력 노드의 개수, 학습의 정확성, 생성된 콘텐츠의 품질에 중요한 영향을 미친다. 음악을 표현하는 방식에는 오디오(audio)와 기호적(symbolic)으로 나뉜다. 오디오는 연속적인 신호, 기호적은 이산적인 신호로 표현된다.
Audio representation
음악을 오디오로 표현하는 방법은 파형(waveform)과 스펙트로그램(spectrogram)으로 2가지 방법이 있다. 그 중에 스펙트로그램은 원본 오디오 신호의 단시간 푸리에 변환(short-time Fourier transform, STFT)을 통해 얻어진다. 오디오 신호 기반 표현 방식의 장점은 원본 오디오 파형(waveform)이 음악의 원래 특성을 유지할 수 있다는 것이다.
그러나 원본 오디오 도메인에서 음악 조각은 일반적으로 연속적인 파형(continuous waveform) $x \in [-1, 1]^T$로 표현되며, T는 오디오 지속 시간(duration), 샘플링 주파수는 16kHz ~ 48kHz이다. 따라서 원본 오디오를 직접 모델링하는 것은 범위 의존적인(range-dependent) 시스템을 초래할 수 있고 음악의 고수준 의미를 학습하는 데 어려움이 생긴다.
Symbolic representation
음악 조각(fragment)의 기호적 표현(symbolic)은 주로 다음과 같다.
a. MIDI 이벤트
MIDI(Musical Instrument Digital Interface)는 다양한 전자 악기, 소프트웨어, 장비 간의 상호 운용성을 보장하는 디지털 인터페이스이다. 그림 3a는 MIDI 이벤트의 유형을 보여준다. 이 방식에서 2개의 기호를 사용하여 음의 시작과 종료를 나타낸다. Note on은 음이 연주되는 시작 지점, Note off은 음이 종료되는 시점을 나타낸다.
그리고 음의 높이(pitch)는 0~127 범위의 정수로 지정된 노트 번호를 통해 표현된다. 이 구조에는 증분 시간 값(incremental time value)이 포함되어 있어 음표 간 상대적 시간 간격을 지정할 수 있다.그러나 MIDI 이벤트 방식은 다중 트랙(multi-track)에서 여러 개의 음을 동시에 연주하는 개념을 효과적으로 보존하지 못하는 한계가 있다.
b. Piano-roll 형식
piano-roll 형식으로 음악 클립을 변환하는 과정은 다음과 같이 진행된다. 먼저 MIDI 파일을 one-hot encoding을 진행한 후 이미지 형식으로 변환한다. 그림 3b에서 x축은 연속적인 시간(time step), y축은 음높이(pitch), z축은 MIDI 트랙을 나타내며 n개의 트랙은 n개의 원-핫 행렬로 표현된다.
piano-roll 형식은 비트를 기준으로 음표를 행렬 형태로 양자화하여 표현한다. 이러한 방식은 멜로디 구조를 쉽게 관찰이 가능하고 다성(polyphonic)음악을 직렬화할 필요가 없기 때문에 음악 생성 시스템에서 널리 사용된다. 그러나 piano-roll 방식에는 아래와 같은 한계점이 존재한다.
- 보컬 및 기타 사운드 디테일(음색(timbre), 속도(velocity), 표현력(expressiveness))을 포착할 수 없음
- 긴 음표와 짧은 음표의 반복을 구별하기 어려움
- 다수의 0 값이 포함되어 있어 학습 효율(training efficiency)이 낮아지는 문제가 있음



c. ABC notation
ABC 표기법(ABC notation)은 멜로디를 텍스트 기반 형식(textual representation)으로 인코딩하는 방식이며 그림 3c에서 확인할 수 있다. 이 방법은 서유럽에서 유래한 전통 음악 및 포크 음악을 위해 특별히 설계되었으나 이후 다른 음악에도 널리 사용되었다. 그러나 주로 단선율(monophonic) 멜로디를 인코딩하는 방식이라 응용 범위가 제한적이고 다성(polyphony) 및 화성(harmony)에 대한 구체적인 표기법이 부족하여 복잡한 다성 음악을 효과적으로 인코딩하는 데 적합하지 않다는 한계점이 존재한다.
Datasets
딥 뉴럴 네트워크 기반 생성 시스템에서는 적절한 음악 데이터셋을 선택하는 것도 중요한 요소이다. 대중적으로 사용되는 공개 데이터셋(popular public datasets)은 멀티트랙, 합창, 피아노, 포크 음악 등 다양한 유형을 포함하며 오디오, MIDI 이벤트, ABC 표기법 등의 다양한 표현 방식을 포함한다. 표 1에는 여러 대표적인 공개 음악 데이터셋의 유형과 인코딩 방식이 나와있다.

Groove MIDI Dataset(GMD)는 총 13.6시간 분량의 통합 MIDI 데이터 및 합성 오디오를 포함하며 인간 연주의 리듬적으로 표현력 있는 드럼 사운드를 수록한다. 총 1150개의 MIDI 파일과 22,000개 이상의 드럼 사운드가 포함된다.
Nottingham Music Dataset(NMD)는 Eric Foxley가 관리하는 데이터셋으로 1000곡 이상의 포크 음악이 특수 텍스트 형식(special text format)으로 저장된다. NMD2ABC와 Perl 스크립트를 사용하여 데이터베이스의 상당 부분을 ABC 표기법으로 변환한다.
기존 연구를 종합적으로 조사한 결과, 현재 사용되는 음악 생성 데이터셋은 서양 장르에 집중되어 있어 동양 장르에 대한 연구는 상대적으로 부족하다. MG-VAE, XiaoIce Band, Jiang et al, CH818, Ajay et al 등의 데이터셋이 있지만 이것들을 제외한 대부분의 데이터셋은 공개적으로 접근하기 어려운 점이 아쉬운 부분이다.
그러나 이런 데이터셋이 존재함에도 불구하고 저작권 문제 및 기타 요인으로 인해 접근성이 제한적이다. 관련 연구 분야의 발전을 촉진하기 위해 보다 포괄적이고 다양한 동양 음악 데이터셋을 구축하는 지속적인 노력이 필요하다. 국제적 협력, 문화적 규범 준수, 데이터 투명성, 기술 혁신 등의 요소가 필수적일 것이다.
Music Generation Systems
현대 음악 생성 시스템의 발전 과정은 초기에 규칙 기반(rule-based) 방법론에서 현재는 딥러닝 기반(deep learning-based) 방법론으로 점진적으로 변화했다. 이러한 발전 과정은 단순하고 짧은 단선율(monophonic) 음악 조각에서 화성을 포함한 복잡한 다성(polyphonic) 음악과 긴 지속 시간의 곡으로 변화하는 경향을 보인다.
본 논문에서는 최신 음악 생성 기술을 조사하고 알고리즘, 장르, 데이터셋, 표현 방식 등의 기준에 따라 분류했다. 세부적인 분류 결과는 표 2에 나와 있으며, 생성 목적에 따라 다음과 같이 단순화하여 분류했다.
- 멜로디 생성(melody generation) : 드럼, 베이스 등의 악기를 위한 멜로디를 생성할 수 있음
- 편곡 생성(arrangement generation) : 화성(harmonies), 주선율(lead melodies), 대위법(counterpoint) 등을 생성할 수 있음
- 오디오 생성(audio generation) : 음악을 직접 오디오 단위에서 모델링하여 다양한 악기와 스타일의 사운드 조각을 생성, 계산복잡도가 높음
- 스타일 변환(style transfer) : 음색 변환, 편곡 스타일 변환 등을 포함, 자동 편곡 기법을 사용하여 특정 작곡가나 음악 장르 또는 특정 악기의 스타일을 원본 곡에 적용
음악 생성 알고리즘은 VAE나 RNN 등과 같이 다양한 기법이 조합되는 사례가 있지만 전반적으로 보면 다음와 같이 4가지로 분류가 가능하다.
- 규칙 기반 시스템(Rule-Based Systems)
- 마르코프 모델(Markov Model)
- 딥러닝 : LSTM(Long Short-Term Memory), VAE(Variational Auto-Encoder), GAN(Generative Adversarial Networks)
- 진화 연산(Evolutionary Computation)
Rule based music generation
규칙 기반 음악 생성 시스템은 비적응적(non-adaptive) 모델로 음악 이론에 기반하여 음악을 생성하는 방식이다. 문법(grammar) 기반 규칙, L-시스템 및 그 변형, 유사성(similarity), 리듬 규칙(rhythm rules) 등의 규칙 기반 제약을 포함한다. 이러한 제약 조건은 지능형 음악 작곡의 과정과 방향을 안내하는 역할을 한다.
규칙 기반 생성 시스템의 성능은 개발자의 창의성, 창작자의 음악적 개념, 음악적 추상화를 변수로 어떻게 표현하는가에 의해 결정된다. 대표적인 규칙 기반 생성 연구는 다음과 같다.
- T. Tanaka et al : 문법적 규칙을 기반으로 리듬을 생성하는 공식을 제안, 이론적 모델에 머물러 있고 실제 구현은 아직 없음
- Miguel et al : 음악 이론에서 도출된 규칙을 기반으로 사용자 감정 입력을 반영, 표현력 문제는 해결했지만 아직 개발 초기 단계에 머물러 있음
- MorpheuS : VNS(Variable Neighborhood Search) 기법을 사용하여 피치를 할당, 반복되는 리듬을 감지하여 특정한 긴장감과 반복적 리듬을 가진 다성 음악 생성, 그림 4에서 작동 원리 확인 가능
규칙 기반 시스템은 탐색 공간을 효과적으로 제한할 수 있고 고도로 구조화된 음악에서도 적용이 가능하다. 그러나 단순한 규칙만으로는 더 깊은 구조를 포착하기 힘들고 규칙이 많아질수록 시스템이 모호해지고(ambiguity 증가), 다양성(diversity)이 제한된다는 한계점이 존재한다.
Markov model
마르코프 모델은 시간 시계열 데이터(time series data)를 처리하는 확률 기반 생성 모델(probability-based generation model)이다. 즉, 샘플 간 시간적 관계가 존재하는 데이터를 다룰 수 있다. 이 모델은 데이터셋 내 특정 요소의 발생 확률과 정의된 특징의 확률을 포착할 수 있다.(ex. 음표 또는 코드의 발생 확률, 음표 또는 코드의 전이 확률 등).
음악 조각은 시간적 특성(temporal nature)을 가지므로, 마르코프 모델은 멜로디(음표 시퀀스, note sequences) 등의 음악 요소를 생성하는 데 적합하다. 대표적인 마르코프 모델 연구는 다음과 같다.
- Chi-Fang Huang et al : 중국 전통 5음 음계의 마르코프 체인 전이 테이블 구축, 현재 입력된 멜로디의 다음 음을 마르코프 체인과 리듬 복잡도 알고리즘 기반으로 생성
- A. S. Ramanto et al : 마르코프 체인 4개를 이용하여 음악 조각의 주요 요소(템포, 음높이, 음 길이, 코드 유형)을 모델링, 각 요소에 대해 다양한 감정 상태에 맞는 파라미터 값을 할당, 그림 5에서 확인 가능
- D. Williams et al : 감정을 기반으로 한 멜로디 생성 모델 제안, 일반적인 마르코프 모델이 아닌 숨겨진 마르코프 모델(Hidden Markov Model, HMM)을 활용
마르코프 모델은 딥러닝 프레임워크와 비교했을 때 더 쉽게 제어가 가능하고 내부 구조에 제약 조건을 부여할 수 있어 알고리즘을 조정하기 용이하다. 그러나 긴 시퀀스에서는 데이터셋의 요소를 비창의적으로 재사용하는 경향이 있다. 즉, 특정 부분이 과도하게 반복될 가능성이 높은 한계점이 존재한다.


Deep learning methods for music generation
구글의 Magenta 프로젝트와 CTRL(Creator Technology Research Lab)에서 이뤄진 연구의 성과와 함께 딥러닝 기반 음악 생성은 더 많은 주목을 받고 있다. 딥러닝 음악 생성 시스템은 기존의 문법 기반 또는 규칙 기반 시스템과 차별화된다. 딥러닝 시스템은 음악 코퍼스(music corpus)에서 샘플의 분포(distribution)와 연관성(relevance)을 학습할 수 있다. 이러한 학습을 바탕으로 딥러닝 모델은 스타일을 반영한 음악을 생성할 수 있으며 예측 또는 분류 방식을 사용한다.
- 예측(prediction) : 멜로디의 다음 음표의 음높이를 예측
- 분류(classification) : 멜로디에 해당하는 코드를 식별
1. Convolutional neural networks
합성곱 신경망(CNN, Convolutional Neural Networks)은 주로 이미지 데이터 처리에 사용되며, 시간 시계열(time-series) 특성을 다루지 않기 때문에 음악 데이터를 처리하는 데 상대적으로 어려움이 있다. 그렇기에 CNN 기반 음악 생성 모델은 현재까지 많지 않다. 그러나 모델 아키텍처 개선 및 정교한 데이터 전처리 기법을 통해 음악 생성이 가능하다.
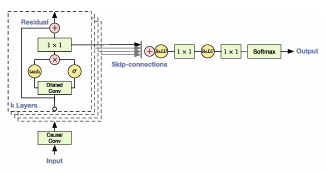
- WaveNet(Google DeepMind, 그림 6)
- 오디오 생성을 위한 CNN 기반 모델
- 확장된 인과적 합성곱(delated causal convolutions) 기법을 도입하여 생성된 오디오 시퀀스를 기반으로 현재 생성할 오디오 데이터의 확률 분포를 예측
- 긴 시간 의존성 문제를 해결했지만 생성된 오디오가 음악적 특성이 약하다는 한계가 존재
- TrimbreTron
- WaveNet의 변형 모델, 음색 변환을 추가하여 다양한 악기 스타일로 변환 가능
- Manzelli et al
- WaveNet 아키텍처를 개선하여 LSTM(Long Short-Term Memory)과 결합
- MusicNet 데이터셋을 활용하여 첼로(cello) 스타일의 오디오 클립을 생성
이 중에서 WaveNet 모델은 다양한 음악 생성 작업에 활용 가능하며 다음과 같은 연구에서 음악 생성과 음악 변환에 적용되었다.
- Engel et al
- WaveNet과 유사한 인코더를 구축하여 숨겨진 시각적 분포 정보를 추론하고 디코더에 입력하여 원본 오디오를 효과적으로 복원, 이를 이용하여 다른 악기의 음색(timbre)으로 변환 가능
- TimbreTron
- 위에서 나온 음악 음색 변환 시스템, CycleGAN을 활용하여 음색을 변환
- 작동 방식
- 오디오 신호의 시간-주파수 표현을 이미지 스타일 변환 기법으로 처리
- 오디오 신호의 Constant-Q 변환을 계산
- 로그 스펙트럼을 이미지로 변환하여 CycleGAN로 학습
- WaveNet 신디사이저를 사용해 고품질 오디오 파형 생성
- 첼로, 바이올린, 일렉 기타 등의 음색 변환 가능
- Coconet
- 합창 자동 보완(AI-based score completion) 모델, 무작위로 삭제된 음표의 특징(feature map of randomly erased notes)을 CNN에 입력하여 자동으로 악보를 보완
2. Recurrent neural networks
Recurrent Neural Networks(RNN)은 시계열 데이터를 처리하기 위한 신경망의 한 종류로, 음악 클립을 처리하는 데 적합하다. 그러나 RNN은 긴 시퀀스 데이터를 처리할 때 기울기 문제가 발생하여 장기 의존성 문제를 해결할 수 없고 이를 해결하기 위해 LSTM이 제안되었다. LSTM은 RNN의 자리를 대신하여 음악 생성 시스템에서 음악 클립을 생성하는데 사용된다.
아래부터는 LSTM이 음악 생성에서 사용되는 예시들을 나타낸다.
- MelodyRNN : Google Brain 팀이 개발, lookback RNN과 attention RNN을 구축하여 긴 시퀀스 학습 능력 향상(그림 7)
- Keerti : 어텐션 메커니즘과 드롭아웃을 도입하여 재즈 음악 생성을 시도
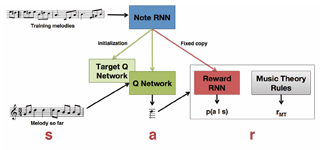
- Rl Tuner : RNN을 이용하여 강화학습 모델에 보상 값을 제공, 단순 멜로디만 생성할 수 있는 한계점 존재
- Folk-rnn : LSTM 네트워크를 이용하여 ABC 표기법으로 음악 시퀀스를 모델링하여 포크 음악을 생성
- DeepBach : 양방향 LSTM을 사용하여 과거와 미래 정보를 모두 반영하고 바흐 스타일 합창 음악 생성
- XiaoIce Band : GRU 기반의 엔드투엔드 멀트 트랙 팝 음악 생성 프레임워크, 인코더-디코더 구조로 다중 악기 음악 생성
- Amadeus : 명시적인 지속 시간 인코딩과 강화학습 보상 메커니즘을 사용하여 음악 구조 개선
- Jambot : 코드 예측용 LSTM과 다성 음악 생성을 위한 다성 LSTM 네트워크 결합
- Song From PI : 계층화된 RNN 모델, 하위 LSTM이 멜로디를 생성하고 상위 LSTM이 드럼과 코드를 생성
3. Generative adversarial nets
Generative Adversarial Nets(GAN)은 고품질 이미지를 생성하기 위한 기법이다. GAN의 핵심 아이디어는 생성자와 판별자를 동시에 훈련시켜 서로 경쟁시키게 만드는 것이다. 최종적으로는 판별자가 실제 데이터와 생성된 데이터를 구분하지 못하는 상태에 도달하는 것이다. 음악에도 적용하려는 연구들이 있지만 아래와 같은 문제점들이 존재한다.
- 음악은 일정한 시간 시퀀스를 가진 데이터이다.
- 음악은 멀티트랙/멀티 악기를 포함한다.
- 단성 음악 생성 방식은 다성 음악에 직접적으로 적용될 수 없다.
아래는 연구자들이 멜로디, 편곡, 스타일 변환 등을 생성하기 위해 GAN 네트워크를 개선한 예시이다.
- C-RNN-GAN : LSTM을 이용하지만 조건부 생성 기능이 부족
- MidiNet : 이전 단계의 멜로디와 코드 정보를 조건으로 활용하여 재즈 작품 생성을 개선(그림 8)
- JazzGAN : 코드 진행 위에 단성 재즈 음악을 즉흥적으로 생성, 관련 평가 지표 제안
- SSMGAN : 음악의 자기 반복을 나타내는 자기 유사도 행렬을 생성, 멜로디를 만듬
- 조건부 LSTM-GAN : 가사를 조건으로 하는 멜로디 생성 모델, 생성자와 판별자 모두 가사를 입력으로 사용

편곡 생성을 위한 모델들의 예시
- MuseGAN : 3가지 유형의 생성기(트랙 내 독립 생성, 트랙 간 전역 생성, 복합 생성)를 포함하는 GAN 모델을 제안, 지나치게 단편화된 노트를 많이 생성하는 문제점이 존재
- Binary MuseGAN : 은 생성기의 입력에 이진 뉴런(BN)을 도입하여 기존 방법을 개선, 판별기가 결정 경계를 학습하기 쉽게 만들고 코드 특성을 감지하기 위한 크로매틱 특징을 도입하여 노트의 과도한 단편화를 줄임
- LeadSheetGAN : 기능적 악보를 조건부 입력으로 사용, MIDI 데이터에 비해 더 많은 정보를 담은 결과를 얻음
스타일 전환과 오디오 생성 측면에서 모델들의 예시
- CycleGAN : 스타일 변환을 위한 스타일 손실 함수와 콘텐츠 손실 함수 도입, 2개의 판별자를 사용하여 생성된 음악이 두 음악 도메인이 병합된 집합에 속하는지 판별
- CycleBEGAN : BEGAN 네트워크를 활용하여 훈련 과정 안정화, 점프 연결을 도입하여 멜로디와 가사의 명료성 높임
- Jin et al. : 생성기로 LSTM 사용, 음악 규칙을 보상 함수로 적용한 Actor Critic을 도입, 생성의 창의성을 높임
- PlayasYouLike : 클래식, 팝, 재즈 음악 간 전환을 구현
- WaveGAN : 원시 웨이브폼 오디오 신호 합성에 GAN 적용
- GAN Synth : 전체 시퀀스를 병렬로 생성, 피치를 나타내는 원-핫 벡터를 추가, 피치와 음색을 독립적으로 제어
이런 음악 생성 성능에도 불구하고 GAN은 여전히 학습이 어렵고 해석 가능성이 떨어지며 텍스트와 유사한 데이터나 음악 악보를 모델링하는 방법에 관한 고품질 연구 결과가 부족하다는 단점이 존재한다.
4. Variational auto-encoder
variantional auto-encoder(VAE)는 인코더와 디코더를 위한 압축 알고리즘으로 다성 음악에서 피치 다이나믹과 악기 편성 등의 정보를 분석하고 생성이 가능하다. VAE의 주 사용 목적은 음악 재조합과 음악 예측의 문제 해결이다. 그러나 데이터가 다중 모달일 경우에는 VAE만으로는 명확하지 못해 RNN 네트워크를 결합한 하이브리드를 사용한다.
아래는 대표적인 예시들이다.
- MIDI-VAE : 그림 9 참고, 3쌍의 인코더/디코더가 잠재 공간을 공유하여 음악의 피치, 강도, 악기 편성을 재구성, 최초의 성공적인 스타일 전환 시도이나 데이터 부족으로 생성 음악 길이가 짧음
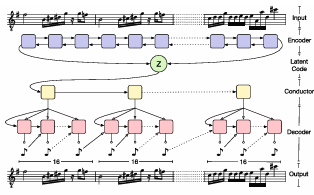
- MusicVAE : 계층적 디코더와 양방향 RNN 인코더를 활용해 장기 구조를 효과적으로 모델링
- GrooVAE : MusicVAE의 변형으로 라이브 전자 드럼 데이터를 학습해 드럼 멜로디를 생성
- Wei et al. : EC2-VAE 기반, 문맥 제약 학습, 대비 학습, 계층적 예측을 도입해 장기 상징적 음악 표현을 최적화하며, 피치와 리듬을 분해함
- Dubnov et al. : 단순 선형 계층으로 음악 표면의 잠재 표현을 학습하고 고해상도 인코딩과 저복잡도 잠재 인코딩 간의 정보 이론적 관계를 통해 음악 창의성에 대한 이론적 틀 제시
- MG-VAE : 동양 음악에 딥 생성 모델과 적대적 훈련을 적용해, 특정 지역 스타일의 민요 음악으로 변환하는 최초의 연구
- Jiang et al. : MusicVAE 기반의 모델, 글로벌 로컬 인코더를 통해 마디, 구절, 곡 수준의 구조를 표현하여 스타일 제어가 가능한 멜로디 생성
- MahlerNet : 조건부 VAE와 두 개의 양뱡향 RNN 인코더(재구성, 문맥 고려)를 사용하여 지속시간, 피치, 악기를 출력함으로써 다양한 악기를 활용한 다성 음악 시뮬레이션
- MIDI-Sandwich2 : 계층적 다중 모달 융합 생성 VAE(MFG-VAE) 네트워크로, 여러 독립 BVAE 모델을 통해 악기별 특징을 추출하고 융합하여 다중 트랙 음악 생성, 기존 Binary MuseGAN의 문제점 개선
- MuseAE : 적대적 오토인코더를 적용하여 KL 다이버전스 대신 적대적 정규화를 사용, 잠재 변수 사전 분포 선택에 더 큰 유연성을 제공
- Jukebox : 원본 오디오 도메인에서 고품질 음악을 생서앟는 시스템, 렌더링이 매우 느려서 실용성에 한계점 존재
5. Transformer
한 곡의 음악은 여러 주제, 구절 또는 다양한 시간의 척도의 반복을 포함하는 경우가 많다. 그렇기에 복잡한 구조를 가진 장기 음악을 생성하는 것은 오랫동안 큰 도전 과제로 남아있었다. 기존의 음악 생성 시스템은 주로 순차적 RNN(or LSTM, GRU) 네트워크를 기반으로 하지만 이러한 방식은 2가지 문제점을 발생시킨다.
- 좌측에서 우측, 우측에서 좌측으로 계산하는 방식은 모델의 병렬 처리 능력을 제한한다.
- 시퀀스 계산 과정에서 일부 정보가 손실될 수 있다.
이러한 한계를 극복하기 위해 Google은 전통적인 CNN이나 RNN 기반 대신 어텐션 메커니즘을 사용하는 Transformer 아키텍처를 제안했고 핵심 아이디어는 입력 간 상관관계를 어텐션 메커니즘으로 표시하는 것이다.
- 데이터 병렬 연산 가능
- 자기 참조(self-reference)의 시각화
- RNN보다 장기 의존성 문제를 더 효과적으로 해결하여 시간적 연속성을 유지
트랜스포머는 위와같은 3가지 장점이 존재하지만 상대적 위치를 나타내는 중간 벡터의 복잡도가 시퀀스 길이에 제곱적으로 증가하기 때문에 음악 생성 작업에서는 적용이 제한된다. 아래는 트랜스포머를 음악 생성에 접한 예시들이다.
- Music Transformer : 상대적 위치 벡터의 공간 복잡도를 줄여 피아노 작곡에 적용, 긴 음악에서는 품질과 구조적 안정성에 한계가 존재
- LakhNES : Transformer-XL과 전이 학습을 통해 칩 음악 생성에 성공
- MuseNet : GPT-2 기반의 대규모 Transformer로 10개의 악기를 포함하는 4분 길이의 음악을 생성, 그러나 악기 배치에 제약이 없이 모든 가능한 노트나 악기의 확률을 계산하는 방식
그림 10에서는 이런 Transformer self-encoder의 흐름도를 볼 수 있다.
Transformer를 다른 모델과 결합하여 문제를 해결하고자 시도했던 연구자들도 존재한다. 아래는 그 예시들이다.
- Transforemr + GAN : GAN 기반 self-attentive 메커니즘과 다중 분기형 적대 구조를 활용하여 단성 음악의 자연스러움을 확보하고 다중 악기 간 조화를 생성하는 방안을 제시
- Transformer + VAE : VAE의 시계열 처리 한계와 Transformer의 잠재 상태 문제를 보완하여 더 효과적인 음악 생성을 가능하게 함
- Transformer 디코더 : 음악의 글로벌 표현을 획득하고 연주 스타일 및 멜로디 제어에 활용하는 접근
아래 연구들은 혁신적인 음악 생성 프레임워크를 제안했다.
- Guo et al. : 커스터마이징이 가능한 제어 토큰을 지원하는 Transformer 기반 인필링 프레임워크
- Zou et al. : 구조 생성 네트워크와 멜로디 생성 네트워크를 결합한 MELONS 제안, 명확한 장기 멜로디 생성
- Dong et al. : 음악 이벤트를 6개의 변수로 구성된 튜플로 인코딩하여 시퀀스 길이를 대폭 줄이고 다양한 악기를 수용할 수 있게 만듬
- Yu et al. : 미세(granular) 어텐션과 거친(coarse) 어텐션을 적용하는 Museformer를 제안

6. Evolutionary algorithms
진화 컴퓨팅 분야는 자연 진화에서 영감을받은 다양한 기술과 방법들을 포괄한다. 이 분야의 핵심에는 고도로 추상화된 생물학적 모델을 기반으로 한 다원주의 탐색 알고리즘이 있다. 높은 품질이나 적응성을 목표로 최적화할 수 있어, 필요한 데이터와 탐색 과정을 압축하거나 확장할 수 있고 지정 가능한 원본 구성 요소로부터 창의적인 음악 아이디어를 생성할 수 있다는 장점이 있다.
진화 알고리즘을 고려할 때는 아래의 3가지 기본 기준을 설정해야 한다:
- 문제 도메인 : 생성할 음악의 유형을 정의한다.
- 개별 표현 : 음악, 멜로디, 하모니, 피치, 지속 시간 등 음악의 각 구성요소를 어떻게 표현할지 결정해야 한다.
- 적합도 측정 : 해결책의 우수성을 평가하는 지표, 표 2 참고(다양한 음악 생성 시스템의 적합도 통계)
초기 진화 알고리즘들은 주로 상호 적응성 측정을 사용했지만 상당한 인간 개입을 요구하며 적응 병목, 낮은 견고성, 적용 범위의 한계, 창의적 잠재력 제한 등의 문제점을 보였다.
아래부터는 진화 알고리즘에서 멜로디를 생성했던 예시이다.
- Munoz et al. : 화성 규칙을 적응 척도로 사용하여 베이스 라인을 기반으로 적절한 멜로디 하위 공간을 탐색, 4부작 고품질 음악 생성
- Jeong et al. : 다중 목적 진화 알고리즘으로 여러 멜로디를 동시에 합성, 소리의 안정성과 긴장도를 적응 척도로 측정
- Lopes et al. : Zipf와 Fux의 법칙을 기반으로 한 두 적응 함수를 활용한 자동 멜로디 합성
- GGA MG : 초기 생성형 유전 알고리즘(GGA)를 통해 데이터셋을 구성하고 Bi-LSTM을 적응 함수로 학습하여 인간 작곡과 유사한 멜로디 생성
여기부터는 편곡 및 화성 생성의 예시이다.
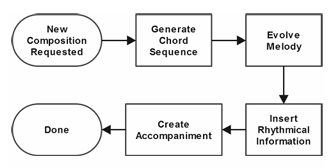
- MetaCompose : 코드, 멜로디, 반주 생성기를 통한 실시간 음악 생성(화성 생성 미포함, 그림 11 참조)
- EvoComposer : 4가지 음성 유형에 대한 화성 생성 및 고전 규칙과 통계 정보를 반영한 적응 함수 도입
- Olseng : 지역/전역 멜로디 및 화성 특징을 활용하여 조화롭고 듣기 좋은 멜로디 생성
- Kaliakatsos : 입자 군집 최적화(PSO)와 유전 알고리즘 기반 MELONS 프레임워크를 통해 구조적이고 풍부한 장기 멜로디 생성
Evaluation
음악 생성 분야에서는 평가하는 것도 큰 도전과제이다. 기존 평가 방법은 주관적 평가와 객관적 평가를 결합하는 경우가 많다. 주관적 평가는 튜링 테스트, 설문조사 등을 포함하고 객관적 평가는 음악 규칙, 코퍼스, 스타일과의 유사성을 기반으로 한 지표들을 포함한다.
Subjective evaluation
음악 생성 시스템의 주관적 평가는 멜로디 출력 측면에서 인간 청취 테스트를 수행하는 방식으로 이뤄진다. 이러한 방법은 튜링 테스트나 설문지와 유사하게 활용된다. 아래는 그 예시들이다.
- MG-VAE : 청취자들이 음악성과 스타일적 의미를 평가하며, 정량적 지표와 결합하여 시스템 성능 평가
- Chen et al. : 상호작용, 복잡성, 구조를 포함하는 수동 평가 지표 제시
- Performance RNN : 생성된 음악에 대해한 사람들의 평가 수집
- Jaques et al. : 인간 평가를 결합하여 음악 생성 시스템의 성능을 판단:
- Amazon Mechanical Turk를 이용하여 참가자들에게 2개의 무작위로 선택된 멜로디 중 선호하는 것을 평가하도록 요청
- 응답자들이 음악 청취 후 화음, 리듬, 전반적인 느낌 측면에서 3모델 중 최상의 모델에 투표
- 사용자 연구를 통해 생성된 음악 클립을 평가하고 평균 의견 점수(MOS)를 비교
이러한 방법들은 합리적일 수 있지만 한계점이 존재한다. 대량의 음악 평가가 어렵고 초기 사용자에게는 피로가 발생한다. 개인 취향 차이로 평가 결과의 불확실성이 생기고 일관성이 저하될 수 있으며, 콘서트나 음악 경연 방식으로 평가할 경우 공연자, 장소, 환경 차이로 인한 편차가 존재할 수 있다.
Objective evaluation
음악 생성 시스템의 객관적 평가는 코퍼스나 스타일과의 유사성, 음악 규칙에 기반한 정량적 지표 등을 포함한다. 음악 생성에서 유사성은 성공의 핵심 척도기 때문에 유사성과 참신성(창의성) 사이의 적절한 균형을 찾는 것이 중요하다. 생성된 음악의 창의성을 평가하는 문제는 복잡한 주제이다.
음악을 객관적으로 평가하는 예시는 아래와 같다.
- Zhang et al. : 서로 다른 음 반복 수, 다양한 피치 개수, 트리플릿 수 등 총 7가지의 객관적 지표 고안
- GANSynth : 음악 조각의 다양성을 측정하는 difference Bins의 수, 초기 점수, 피치 정확도, 피치 엔트로피 등을 활용
- JazzGAN : 패턴 붕괴, 창의성, 화성/코드 지표를 사용
- MuseGAN : 한 트랙 내에서와 트랙 간의 차이를 평가하기 위해 여러가지 지표를 설계
음악 생성 시스템의 객관적 평가에서 가장 큰 과제는 시스템의 우수성을 판단하는 단일 객관적 평가 기준이 존재하지 않는 다는 점이다. 이러한 기준들은 현재의 특정 음악 생성 작업에만 적용 가능하기 때문에 일반화하기 어렵고 타당성에 대한 추가적인 검토가 필요하다.
Anaylysis and perspectives
Current state of intelligent music generation
음악 생성 시스템은 아래와 같은 여러가지 장점이 존재하여 개발 전망과 상업적 가치가 매우 높다.
- 음악 1분 당 비용이 작곡가보다 낮음
- 사용자 설정에 따라 음악을 맞춤화, 개인화가 가능
- 작곡가에게 영감을 주거나 도움을 제공
- 음악 교육 등의 용도로 활용 가능
실제로 Melodrive가 게임 환경에서 즉각적인 음악 생성을 하고 Amper Music이 몇 초 만에 개인 맞춤형 오리지널 음악을 생성하고 Ambient Generative Music이 다양한 환경에서 자동으로 개인화된 음악을 생성하는 사례들이 있다.
그러나 아직도 아래와 같은 몇 가지 어려움이 존재한다.
- 완전한 구조를 갖춘 긴 시간 시리즈의 음악 조각을 구성하기 어렵다
- 생성된 음악을 평가하기 어렵다
MuseNet처럼 10개의 서로 다른 악기를 사용해 4분 길이의 음악 작품을 생성하는 경우도 있지만 최신 음악 생성 알고리즘들은 시간이 길어질 수록 음악성이 저하되는 문제를 겪고 있다. 현재 연구자들은 음악 이론 지식을 바탕으로 생성 알고리즘을 최적화하거나 생성된 음악 조각에 제약을 부과하는 방식등으로 문제를 완화하는 데 주력하고 있다.
Comparative analysis of music generation research in eastern and western contexts
서양의 음악 생성 연구는 OpenAI, Google, AIVA와 같이 온라인으로 접근 가능한 도구들을 제공할 정도로 성숙한 단계에 도달했지만 동양에서는 이 분야의 연구가 아직 초기 단계에 머물러 있다. 일부 동양 기업과 연구 기관들이 이 분야를 적극적으로 탐구하고 있으나 동양 고유 음악 장르에 초점을 맞춘 연구는 상대적으로 제한적이다.
동양 음악은 구조, 음악적 사고, 예술적 표현 면에서 서양 클래식 음악과 다르다. 동양 음악 장르는 주로 단선율의 단성 음악을 구성하며 음악의 미학을 강조하지만 서양 음악에서는 다성 음악에 초점을 맞추며 장조와 단조를 강조하고 화성 논리, 반복, 대비, 확장 등의 기법을 통해 분위기를 조성한다. 또한 예술적 표현 측면에서 서양음악은 주관성과 객관성의 대비를 강조하지만 동양 음악은 통일성을 중시하며 즉흥 연주 요소가 많아서 보다 유연하고 다양한 리듬을 만든다.
결국 동서양 음악 간의 구조, 내용, 연주 방식의 내재적 문화적 차이로 인하여 음악 생성 시스템은 각각의 특성에 맞춰 광범위한 조정과 최적화가 필요하게 되어, 동서양 음악 생성 시스템 간의 보편성이 낮아지는 결과를 초래한다.
다양하고 고품질의 동양 음악 코퍼스가 부족한 것은 동양 음악 장르에 초점을 맞춘 음악 생성 시스템 발전을 제한하는 또 다른 요인이다. 서양 음악 데이터셋과 비교해서 동양 코퍼스는 양과 질이 모두 부족하여 고유한 특징을 파악하기 힘들며 이런 데이터베이스의 부재는 음악 스타일에 맞춘 생성 기술 발전을 저해한다. 또한 동양 민족 음악을 수집하는 과정이 복잡하고 까다로우며 저작권 문제가 있어 음악 생성 연구 발전에 제약이 생긴다.
또 다른 문제는 음악 생성 시스템에 대한 효과적인 평가 방법과 객관적 평가 기준의 부재이다. 음악 생성에서는 인간 평가에 크게 의존하는 경우가 많은데 동양 음악은 독특하고 다양한 장르를 지니고 있어서 동양 음악 장르에 대한 분석이 제한적일 수 밖에 없다. 그렇기에 적합한 데이터를 얻기 어렵고 이런 문제들이 합쳐서 동양 음악 생성 연구의 발전을 제한한다.
음악 이론과 엄격한 규칙들이 생성 시스템을 강화하는 데 중요한 역할을 할 수 있다. 그러나 동양 연구자들은 한 분야에 특화되어 있는 경우가 많아 음악의 기본 원리를 생성 모델과 통합할 수 있는 지식이 부족하다. 이러한 차이가 동서양 음악의 불균등한 발전을 초래한다. 그리고 음악 생성 특성상 음악 이론이 가지고 있는 복잡성 때문에 전문적 지도 없이 음악 이론적 구성 개념을 포괄적으로 학습하는 것은 어렵다.
이러한 문제들을 해결하기 위해서는 연구 자금과 교육 프로그램 확대, 학제간 협력 및 국제 협력 강화, 체계적 데이터 수집과 표준화된 평가 기준 수립 등이 필요하다. 세계화된 사회에서는 음악 문화가 서로 융합되고 있으며 동서양의 이분법적 구분에서 벗어나 지역적, 전통적, 현대적 특성에 초점을 맞춘 심도 있는 분석이 앞으로의 음악 생성 모델 발전에 기여할 것으로 예상된다.
Trends in artificial intelligence music
1. Music generation technology moves towards maturity
현재 음악 생성 시스템은 주로 가사 또는 멜로디 생성에 집중한다. 음악과 가사 또는 음악과 영상처럼 서로 다른 정보를 동시에 생성하는 크로스 모달 음악 생성이 향후 인공지능 음악 분야 발전의 중요한 방향이 될 것이다. 다양한 모달리티에 걸친 특징 추출 및 융합을 필요로 하기 때문에 일정한 기술적 도전을 동반할 것이다. 음악 생성 시스템은 앞으로 보다 견고한 음악 데이터 아키텍처와 표준화된 테스트 데이터셋 및 평가 지표를 활용하여 개선될 수 있다.
현재 딥러닝 아키텍처가 음악 생성 시스템의 주류 방식이므로 딥 네트워크의 해석 가능성과 제어력을 향상이 미래 음악 생성 기술의 중요한 방향이 될 것이다. 또한 음악 생성시 발생하는 시간적 의존성 문제를 해결하고 음표 단위가 아닌 세그먼트 다누이의 오디오 생성을 연구하는 것도 미래에 중요한 주제이다.
2. Emotional expression of music generation and its coordinated development with robot performance
음악은 인간 감정 표현의 가장 중요한 형태 중 하나이다. 현재의 음악 생성 수준은 신호 분석에 기반해 있어, 음악적 감정을 인식하는 인간 중심 시스템이나 인간적인 작곡 사고가 도입되지 않았다. 따라서 컴퓨터 비전, 청각 등 다양한 정보를 통합하여 인간의 음악 감정 스펙트럼과 오디오 표현 체계를 인식하고 딥러닝 등의 기법을 활용하여 음악 생성의 감성 차원을 최적화 하는 것이 미래 지능형 작곡 시스템의 주 목표이다.
또한 로봇 시스템 기반 음악 시각화 연구와 감정적으로 상호작용하는 음악 치료 로봇은 로봇 기술과 음악 표현을 통합하여 로봇을 중심 요소로 삼고 있다. 이것도 통합 발전에 있어 중요한 하이라이트가 될 것이다.
https://link.springer.com/article/10.1007/s00521-024-09418-2