Introduction
최근 이미지, 음성, 비디오 생성 모델 분야가 발전하면서 인상적인 결과물을 만들고 있다. few-shot learning, 강화학습과 같은 어려운 문제들은 데이터로부터 유용한 표현을 학습하는 것이 중요하지만, 비지도 학습으로 좋은 표현을 얻는 방법은 아직 보편적으로 사용되지 못하고 있다.
현재 비지도 학습 모델들은 주로 MLE나 복원 에러를 기준으로 훈련되지만, 이 기준들의 유용성은 적용되는 분야에 따라 달라지는 한계점이 있다. 본 논문에서는 MLE를 최적화하면서도 데이터의 중요한 특징을 잠재 공간에 잘 보존하는 모델을 만드는 것이다. 우리는 이산적이고 유용한 잠재 변수를 학습하는 것이 중요하다고 생각하며, 우리의 접근법이 효과적임을 증명할 것이다.
연속적인 특징의 표현을 학습하는 것은 과거 많은 연구들에서 집중했지만 우리는 더 포텐셜이 있는 이산적 표현에 집중했다. 언어, 음성, 이미지와 같은 데이터는 본질적으로 이산적 표현이 더 자연스럽고 적합하기 때문이다. 나아가, 이산적 표현은 복잡한 추론, 계획, 예측 학습에도 더 유리하다. 이산적 잠재 변수를 딥러닝에서 사용하는 것은 기술적으로 어려운 문제지만, 다행히 강력한 자기회구 모델과 같은 기술들이 개발되어 왔다.
우리는 VAE 프레임워크와 이산적 잠재 표현을 결합한 새로운 생성 모델을 소개할 것이며, 이는 사후 분포를 새롭게 매개변수화하는 독창적인 방식을 사용한다. 우리의 모델은 vector quantization(VQ)에 의존하며 아래와 같은 장점이 존재한다.
- 학습이 간단함
- 결과불의 분산이 크지 않아 안정적임
- 기존 VAE의 고질적 문제인 사후 붕괴(잠재 변수가 무시되는 문제)를 피함
이 모델은 이산 잠재 변수를 사용하면서 기존 모델들과 유사한 성능을 내는 최초의 VAE 모델이다. 우리는 이 모델을 VQ-VAE라고 부른다.
VQ-VAE가 잠재 공간을 효율적으로 사용하기 때문에, 데이터의 '큰 그림'에 해당하는 중요한 특징들을 성공적으로 잡아낼 수 있다. 이는 국소적인 노이즈나 세부적인 정보에 대한 모델의 표현 능력을 낭비하는 기존 방식들과 대조된다.
마지막으로, VQ-VAE에 의해 좋은 이산적 잠재 구조가 만들어지면 이 잠재 변수들 위에 강력한 사전 분포 모델을 추가로 학습시킨다. 원본 음성 데이터만으로도 어떠한 지도나 사전 지식 없이 언어의 잠재적 구조를 스스로 발견한다. 말의 내용은 그대로 둔 채, 목소리만 다른 사람으로 바꾸는 것도 가능하며 강화학습 환경의 장기적인 구조를 파악하는 데에도 좋은 성능을 보였다.
본 논문의 기여는 아래처럼 요약할 수 있다:
- 간단하고, 이산적 잠재를 사용하고, 사후 붕괴가 없는 VQ-VAE 모델을 제안
- VQ-VAE가 로그 가능도 성능 면에서 연속 잠재 변수 모델과 대등함을 보임
- 강력한 사전 분포 모델과 결합했을 때, 음성 및 비디오 생성 등에서 일관성 있고 품질이 뛰어난 결과물을 생성
- 지도 없이 원본 음성만으로 언어를 학습하고, 이를 응용해 비지도 방식의 화자 변환이 가능함을 보임
Related Work
본 논문에서는 variatioanl autoencoder를 이산적 잠재 변수와 함께 훈련하는 새로운 방법을 보였다. 데이터의 본질이 이산적이지만 대부분의 연구에서 연속 잠재 변수가 쓰이는 현실은 이산 변수를 딥러닝에 적용하는 것이 어려운 문제임을 보여준다.
이산적 VAEs를 학습시키는 것에는 다양한 방법들이 존재한다:
- NVEL estimator : 단일 샘플을 사용해 변분 하한을 최적화하고 분산 감소 기법을 사용해 학습 속도를 높임
- VIMCO : 여러 개의 샘플을 사용해 NVIL보다 수렴 속도를 개선함
- Concrete / Gumbel-Softmax
- 이산적인 문제를 풀기 위해 연속 분포를 사용하는 재매개변수화 기법
- 온도라는 상수를 학습 중에 점차 낮추는 방식, 연속 분포를 점차 이산 분포에 가깝게 만듬
- 학습 초반에는 기울기의 분산이 낮은 대신 편향이 높고, 학습이 끝날 무렵에는 편향이 낮은 대신 분산이 높음
위에서 언급된 어떤 기법도 연속 잠재 변수 VAE와의 성능 격차를 좁히지 못했다. 이는 연속 VAE가 가우시안 재매개변수화 기법 덕분에 훨씬 안정적이고 낮은 분산의 그래디언트로 학습할 수 있기 때문이다. 게다가 기존 기법들은 대부분 MNIST와 같은 작고 간단한 데이터셋에서 매우 낮은 차원의 잠재 공간으로만 평가되었다. 이와 대조적으로 우리는 3가지의 복잡한 이미지 데이터셋(CIFAR10, ImageNet, DeepMind Lab)과 원본 음성 데이터(VCTK)를 사용했다.
본 논문은 아래의 분야와 연관이 있다:
- 자기회귀 모델:
- VQ-VAE는 VAE의 디코더나 사전 분포에 강력한 자기회귀 모델을 사용하는 연구 흐름의 연장선에 있다.
- 과거에는 LSTM이나 Dilated Convolutional Net, 이미지 생성에 뛰어난 PixelCNN과 같은 자기 회귀 모델들이 VAE의 디코더로 사용되었다.
- 이미지 압축:
- 최종적으로 우리의 방식은 네트워크를 사용한 이미지 압축과도 관련이 있다.
- 기존 압축 연구들에서 활성화 값을 압축하기 위해 스칼라 양자화나 벡터 양자화를 사용했다. 이는 VQ-VAE의 핵심 아이디어와 맞닿아 있다.
한 선행 연구에서는 연속 근사라는 기법을 제안했다. 이는 벡터 양자화를 학습시키기 위해 점진적으로 어닐링(annealing)하는 복잡한 soft-to-hard 방식을 사용한다. 하지만 본 논문의 저자들이 해당 기법을 사용해 모델을 처음부터 학습시키려 시도했을 때, 이는 불가능했다. 학습 과정에서 디코더가 이 연속 근사 기법을 그냥 무효화시켜 결과적으로 의도했던 양자화가 전혀 일어나지 않는 문제가 발생했다. 이런 실패는 VQ-VAE가 제안하는 더 직접적이고 안정적인 새로운 접근법의 필요성을 보여준다.
VQ-VAE
우리의 방법과 관련있는 대부분의 연구는 VAE다. VAE는 아래의 구성요소로 되어 있다:
- 인코더 : 입력 데이터 $x$를 받아 잠재 변수 $z$의 확률 분포인 사후 분포 $q(z|x)$를 출력
- 사전 분포 $p(z)$ : 잠재 공간 자체에 대한 확률 분포
- 디코더 $p(x|z)$ : 잠재 변수를 받아 원본 데이터를 복원하는 확률 분포를 출력
일반적인 VAE에서는 사후/사전 분포가 정규 분포라고 가정한다. 이 가정 덕분에 가우시안 재매개변수화 기법을 사용할 수 있어, 안정적으로 모델을 학습시킬 수 있다. 더 나아가 자기회귀 모델이나 정규화 흐름 등을 결합해 VAE를 더 정교하게 만들기도 한다.
우리는 벡터 양자화(VQ)에서 영감을 받아 이산적 잠재 변수를 사용하는 VQ-VAE를 소개한다. 핵심적인 차이는 다음과 같다:
- VQ-VAE의 사후/사전 분포는 정규 분포가 아닌 범주형 분포를 사용
- 이 분포에서 샘플을 추출하면 특정 인덱스가 나옴
- 인덱스를 사용하여 미리 정의된 임베딩 테이블에서 해당하는 고차원 벡터를 조회
- 최종적으로 이 임베딩 벡터가 디코더의 입력으로 사용
Discrete Latent variables
우리는 잠재 임베딩 공간 $e \in R^{K \times D}$를 정의한다:
- $K$ : 이산적 잠재 공간의 사이즈
- $D$ : 각 잠재 임베딩 벡터 $e_i$의 차원
- $K$ 개의 임베딩 벡터 $e_i \in R^D$가 존재함
VQ-VAE의 순전파 과정은 아래와 같다:
- 아래의 식처럼 모델은 입력 $x$를 받아 인코더를 통해 연속적인 벡터인 $z_e(x)$를 출력한다.
- 인코더의 출력 $z_e(x)$와 임베딩 공간 $e$에 있는 $K$개의 벡터들 간의 거리를 각각 계산한다. 그중 가장 가까운 임베딩 벡터를 하나 선택하고, 그 벡터의 인덱스를 이산 잠재 변수 $z$로 결정한다.
- 디코더는 2단계에서 선택된 실제 임베딩 벡터 $e_k$를 입력으로 받아 원본 데이터를 복원한다.
이 전체 과정은 인코더와 디코더 사이에 가장 가까운 임베딩 벡터를 찾아주는 특별한 비선형 함수가 삽입된 오토인코더로 이해할 수 있다. 이 모델에서 학습을 통해 최적화되는 파라미터는 인코더 디코더뿐만 아니라 임베딩 공간 $e$ 자체도 포함된다. 즉, 데이터에 가장 적합한 코드북을 스스로 학습한다. 지금까지는 설명을 위해 잠재 변수 $z$가 하나인 것처럼 설명했지만, 실제 이미지나 음성 같은 데이터에 적용할 때는 1D, 2D, 3D 형태의 격자나 공간을 형성한다.
사후 범주형 분포 $q(z|x)$의 확률은 아래와 같이 one-hot으로 정의된다(식1):
$$
q(z = k \mid x) =
\begin{cases}
1 & \text{for } k = \arg\min_j \lVert z_e(x) - e_j \rVert_2, \\
0 & \text{otherwise}
\end{cases}
$$
- $z_e(x)$: 디코더 네트워크의 출력
- VAE 프레임워크를 따르므로 학습 목표는 ELBO가 됨
- $q(z = k|x)$는 결정론적(균등 분포로 가정)
- 이렇게 되면 KL 발산 항이 $\log K$라는 상수가 되어 학습을 단순화하고 안정시킴
인코더의 출력 $z_e(x)$는 이산화 병목 과정을 거친다. 이 과정을 거친 최종 결과물, 즉 디코더에 실제로 입력되는 벡터는 $z_q(x)$로 표시한다(식2):
$$z_q(x) = e_k, \quad \text{where} \quad k = \arg\min_j \|z_e(x) - e_j\|_2$$
Learning
식 2에는 미분이 불가능하다. 이 때문에 역전파 방식으로는 디코더에서 인코더로 그래디언트를 전달할 수 없다. 이 문제를 해결하기 위해 Straight-Through estimator와 유사한 근사법을 사용한다. 역전파 과정에서 디코더의 입력 $z_q(x)$에서 온 그래디언트를 그대로 복사하여 인코더의 출력 $z_e(x)$으로 전달한다.
이 방법이 효과적인 이유는 인코더의 출력 $z_e(x)$와 디코더의 입력 $z_q(x)$가 동일한 $D$ 차원 공간을 공유하기 때문이다. 디코더 쪽에서 온 그래디언트는 비록 근사값이지만 인코더가 재구성 손실을 낮추기 위해 자신의 출력을 어느 방향으로 업데이트해야 하는지에 대한 유용한 신호를 제공한다.
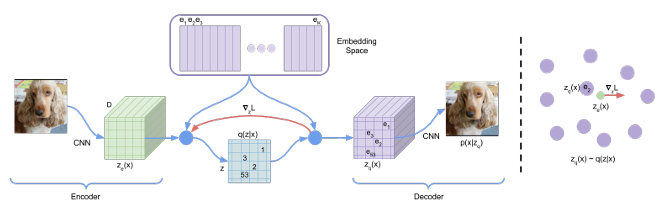
그림 1의 오른쪽에서 묘사되듯이, 이 그래디언트를 통해 인코더가 업데이트되면 다음 순전파에서 인코더의 출력 $z_e(x)$값이 바뀐다. 바뀐 $z_e(x)$는 이전과 다른 임베딩 벡터를 가장 가까운 이웃으로 선택할 수 있고, 이 과정을 반복하면서 인코더는 더 좋은 이산 잠재 코드를 생성하도록 학습된다.
식 3은 전체적인 손실 함수를 구체화한다. VQ-VAE의 다른 부분을 학습시키기 위해 3가지 구성을 사용한다:
- 재구성 손실
- 디코더와 인코더를 최적화하여 입력 데이터를 잘 복원
- 벡터 양자화(VQ) 손실
- 그래디언트를 복사해서 전달하기 때문에 임베딩 $e_i$는 재구성 손실 $\log p(z|z_q(x))$로부터 그래디언트를 받지 않음
- 임베딩 공간에 대해 학습하기 위해 단순한 단어적 학습 알고리즘 Vector Quantisation 사용
- $l_2$ 오차를 사용하여 인코더의 출력 $z_e(x)$와 그것이 선택한 가장 가까운 임베딩 벡터 $e_k$ 사이의 거리를 좁히도록 학습함, 코드북의 벡터들을 인코더의 출력 쪽으로 끌어당기는 역할
- 전념 손실(Commitment Loss)
- 인코더의 출력이 임베딩 공간의 벡터들로부터 너무 멀리 떨어져 나가며 발산하는 것을 막기 위함
- 인코더가 특정 임베딩 벡터에 전념(commit)하도록, 가까이 머무르도록 규제하는 손실
- 이 손실의 그래디언트는 오직 인코더에만 영향을 줌
위의 손실들을 종합한 학습 목적은 아래와 같다(식3):
$$L = \log p(x|z_q(x)) + \|sg[z_e(x)] - e\|^2_2 + \beta \|z_e(x) - sg[e]\|^2_2$$
- sg : 그래디언트의 흐름을 제어하는 핵심 장치, 역전파 시, sg가 감싸고 있는 항으로는 그래디언트가 흐르지 않도록 차단
- 이 장치 덕분에 각 손실 항이 자신이 업데이트해야 할 대상에게만 정확히 영향을 미치도록 만듬
- 디코더는 첫번째 항(재구성 손실)만으로 최적화
- 인코더는 처음(재구성 손실)과 마지막 항(전념 손실)으로 최적화
- 임베딩은 가운데 항(VQ 손실)을 통해 최적화
- 전념 손실의 가중치를 나타내는 $\beta$ 값에 모델 성능이 크게 민감하지 않았음
우리는 $z$를 위해 균일한 사전 분포를 가정했기 때문에 ELBO의 KL 항은 상수로 나타나며 훈련 도중에 무시할 수 있다. 우리 실험에서 $N$개의 잠재 변수 격자를 사용하며, 이때 VQ 손실과 전념 손실은 $N$개 항의 평균으로 계산된다.
학습은 ELBO로 진행하지만 모델의 최종 성능을 나타내는 정확한 로그 가능도는 모든 잠재 코드 $k$에 대해 확률을 합하는 별도의 수식으로 계산이 가능하다:
$$\log p(x) = \log \sum_k p(x|z_k)p(z_k)$$
디코더는 학습 시 오직 가장 가까운 양자화된 벡터 $z_q(x)$만을 입력으로 받기 때문에, 학습이 완료되면 $z \neq z_q(x)$인 다른 잠재 코드에 대해서는 확률을 할당하지 않게 된다. 이 가정을 통해 우리는 $\log p(x) \approx \log p(x|z_q(x))p(z_q(x))$로 나타낼 수 있다. Jensen's 부등식에서 우리는 $\log p(x) \geq \log p(x|z_q(x))p(z_q(x))$도 얻을 수 있다.
Prior
VQ-VAE는 사전 분포 p(z)를 직접 학습하지 않고 아래의 전략을 사용한다:
- 학습시키는 동안 사전 분포를 단순한 균등 분포로 고정, 오직 좋은 표현을 배우는 데 집중
- 학습이 끝나면 학습된 파라미터는 고정
- 그 후, VQ-VAE가 만들어내는 이산 잠재 코드들의 복잡한 분포 $p(z)$를 학습하는 별도의 강력한 자기회귀 모델을 훈련
- 이미지에서는 PixelCNN, 오디오에서는 WaveNet을 사용
Experiments
Comparison with continuous variables
첫 실험으로 우리는 VQ-VAE의 성능을 일반적인 연속 VQE와 기존의 이산 VQE 방식인 VIMCO와 비교 평가한다.
- 실험 조건
- 데이터셋: CIFAR10
- 실험 변인: 잠재 용량(잠재 변수의 개수나 이산 공간의 차원을 바꿔가며 성능을 비교)
- 모델 구조
- 모든 모델은 동일한 기본 VAE 구조를 사용
- 인코더: 2개의 4x4 스트라이드 합성곱 레이어와 2개의 3x3 잔차 블록
- 디코더: 2개의 3x3 잔차 블록과 2개의 4x4 전치 합성곱
- 모든 레이어의 히든 채널 수는 256개
- 학습 설정
- ADAM 옵티마이저 사용
- 학습률: 2e-4
- 배치크기: 128
- 총 학습 스텝: 250,000
- VIMCP: 학습 시 50개의 샘플을 사용
VAE, VQ-VAE, VIMCO 모델은 각각 4.51 비트/차원, 4.67 비트/차원, 5.14 비트/차원을 얻었다.우리가 구현한 일반 VAE의 성능은 기존 다른 연구에서 보고된 수치(4.54 비트/차원)과 비슷하다. 이는 실험의 설정이 타당함을 의미한다.
VQ-VAE는 연속 VAE만큼 이미지를 잘 복원하며 이산 표현의 장점을 가지는 결과를 보였다.
Images
이미지는 대부분의 픽셀들이 서로 비슷하고 노이즈가 많아 픽셀 단위로 직접 모델링하는 것은 낭비로 여겨진다. 우리 실험에서는 2단계의 접근법을 사용해 이를 해결했다.
- 1단계(압축): $x = 128 \times 128 \times 3$의 이미지를 $z = 32 \times 32 \times 1$의 이산적 공간($K=512$)로 압축, 이렇게 하면 $\frac{128 \times 128 \times 3 \times 8}{32 \times 32 \times 9} \approx 42.6$의 비스트를 아낄 수 있음
- 2단계(사전 분포 학습): 압축된 32x32 이산 잠재 공간 위에서 강력한 사전 분포 모델인 PixelCNN을 학습시킴
이런 접근 방식을 사용할 경우 저해상도 잠재 공간에서 PixelCNN을 학습시키기 때문에 학습 및 새로운 이미지 샘플링 속도가 매우 빨라진다. 그리고 PixelCNN이 픽셀 단위의 자잘하고 국소적인 통계를 학습하는 데 용량을 낭비하는 대신 압축된 잠재 공간의 핵심적이고 전역적인 구조를 포착하는 데 집중할 수 있다.

$32 \times 32 \times 1$의 이산적 잠재 공간에서 이미지를 복원하는 작업은 그림 2에서 확인 가능하다. 차원을 엄청나게 줄였음에도 불구하고 복원된 이미지는 원본과 비교했을 때 아주 약간 흐릿해지는 정도였다. MSE보다 더 지각적인 손실 함수를 사용한다면 더 좋은 성능이 나올 것이지만 이것은 후속 연구이다.
그 후, 우리는 PixelCNN 사전 분포를 이산적 $32 \times 32 \times 1$의 잠재 공간에서 학습했다. 우리는 오직 1개의 채널만을 가지고 있기에 PixelCNN에서 공간적 마스킹만 사용하면 되어 구조가 더 간단해지는 이점이 있다.

PixelCNN을 이용하여 나온 샘플들은 VQ-VAE의 디코더에 매핑되며 이는 그림 3에서 확인 가능하다.

우리는 DeepMind Lab 환경의 이미지($84 \times 84 \times 3$) 를 대상으로 똑같은 실험을 진행했다. 재복원된 이미지는 원본과 거의 동일한 수준으로 매우 높았다. 압축된 $21 \times 21 \times 1$ 크기의 잠재 공간에서 학습된 PixelCNN 사전 분포를 이용해 새로운 이미지를 성공적으로 생성했으며 그 결과는 그림 4에서 확인할 수 있다.
최종적으로 우리는 $21 \times 21 \times 1$ 크기의 잠재 공간으로 압축하고, 이 잠재 공간 자체를 입력으로 삼아 강력한 PixelCNN을 디코더로 사용하는 두 번째 VQ-VQE를 그 위에 학습시켰다. 일반 VAE라면 사후 붕괴가 발생할 설정이지만, VQ-VAE는 문제 없이 잠재 변수를 의미 있게 사용함을 확인했다. 2단계의 VQ-VAE는 단 3가지의 잠재 변수를 사용했기에 몇몇 모델은 이미지를 완벽히 재복원하지는 못했다. 그래도 극소수의 전역 코드만으로도 이미지의 전체적인 형태를 재구성할 수 있음을 보여주며, 재복원 이미지는 그림 5에서 확인 가능하다.

Audio
이번 실험에서는 이산적 잠재 변수를 원본 오디오에 대해 평가했다. 우리의 오디오 실험에서 VQ-VAE를 WaveNet 디코더와 비슷한 확장된(dilated) 합성곱을 사용했다. 모든 샘플은 아래 링크에서 재생할 수 있다:
https://avdnoord.github.io/homepage/vqvae/.
Aäron van den Oord ·
Neural Discrete Representation Learning All samples on this page are from a VQ-VAE learned in an unsupervised way from unaligned data. More details in the paper. Reconstructions These samples are reconstructions from a VQ-VAE that compresses the audio inpu
avdnoord.github.io
정보의 추상화 및 분리 능력 검증
우리는 처음에 109명의 다른 화자가 있는 VCTK 데이터 셋을 사용했다. 인코더는 스트라이드 2, 윈도우 크기 4를 갖는 6개의 스트라이드 합성곱 레이어로 구성된다. 이 구조는 원본 오디오 파형을 64배 작은 잠재 공간으로 압축하는 효과가 있다. 잠재 공간은 1차원의 특징 맵 형태이며, 이산 코드북의 크기는 512이다. 디코더는 VQ-VQE가 추출한 잠재 코드와 화자가 누구인지를 나타내는 원-핫 임베딩의 정보를 입력으로 받는다.

이 실험은 VQ-VAE가 오디오 신호에서 장기적으로 중요한 정보(말의 내용)만 보존하고 단기적이고 덜 중요한 저수준 특징은 걸러내는지 확인하기 위해 진행했다. 학습된 VQ-VAE에 원본 오디오를 입력하여 이산 코드로 압축한 뒤, 다시 디코더로 복원한다.
- 이산적 표현의 차원이 64배 더 작기 때문에 원본 샘플은 완벽하게는 재복원될 수 없음
- 그림 6에서 확인할 수 있듯이 복원된 음성은 아래의 특징을 가짐
- 보존된 것: 말의 내용은 원본과 동일
- 버려진 것: 파형의 모양이나 목소리의 운율, 억양, 톤
이 결과는 VQ-VAE가 어떠한 언어적 지도(supervision) 없이도 스스로 음성 신호에서 중요한 것과 중요하지 않은 것을 구분하여 학습했음을 의미한다. 즉, VQ-VAE는 음성의 내용만을 인코딩하는 고수준의 추상적인 잠재 공간을 학습했다.
비 조건부 생성 능력 평가
그 후에 아무런 입력 오디오 없이, 학습된 사전 분포만으로 새로운 오디오를 생성하여 모델의 최종적인 생성 능력을 평가했다.
- 실험 설정
- 데이터 셋: 460명의 화자가 포함된 더 큰 데이터셋
- 압축률: VQ-VAE의 압축률을 더 높여 잠재 공간의 해상도를 원본 오디오보다 128배 낮춤
- 사전 분포 학습: 압축된 잠재 공간 위에서 강력한 자기회귀 모델을 학습
- 생성 품질 비교 및 결과
- 한계: 최상급 음성 생성 모델인 WaveNet조차도 비조건부로 샘플을 생성하면 옹알이처럼 들리는 한계가 존재
- VQ-VAE: 명확한 단어와 문장의 일부를 포함하는 높은 품질과 일관성을 보임
이 결과는 VQ-VAE가 어떠한 텍스트나 발음 기호 정보 없이, 오직 원본 오디오 파형만 듣고도 놀라운 성과를 달성했음을 의미한다. 비지도 방식으로 음소(phoneme) 수준을 이해하고 기초적인 언어 모델을 학습하는 데 성공했다.
화자 변환 실험
이번에는 한 화자로 인코딩하고 다른 화자의 아이디로 디코딩하는 경우를 생각해보자. VQ-VAE가 학습한 잠재 코드가 화자의 목소리 특징과 분리되어 내용 정보만 담고 있는지를 확인한다. 실험 결과 생성된 음성은 원래의 화자와 동일하지만 목소리는 바꾼 화자의 특징을 가진다. 이 실험은 VQ-VAE가 순수한 내용 정보를 성공적으로 학습했음을 다시 한 번 입증한다.
잠재 코드와 실제 음소 비교
완전한 비지도 방식으로 학습된 이산 잠재 코드가 실제로 언어의 기본 단위인 음소와 얼마나 관련이 있는지 정량적으로 분석한다.
- 실험 방법
- 학습된 128개의 이산 코드가 어떤 음소에 가장 자주 대응되는지 매핑
- 이 매핑 규칙을 사용해 잠재 코드 시퀀스를 음소 시퀀스로 변환, 실제 정답 음소 시퀀스와 비교
- 결과
- VQ-VAE 잠재 코드를 이용한 음소 분류 정확도는 49.3%를 기록
- 무작위 기준선의 정확도인 7.2%에 비해 높은 수치
이 결과는 VQ-VAE가 완전한 비지도 방식으로 원본 오디오만 듣고 핵심 구성 요소인 음소와 매우 밀접하게 관련된 고수준의 표현을 스스로 학습했음을 보인다.
Video
마지막 실험은 액션 시퀀스가 주어졌을 때 생성 모델을 DeepMind Lab 환경에서 훈련하는 것이다. 예측과 생성은 픽셀 공간이 아닌, 전적으로 압축된 잠재 공간 안에서 이뤄진다.
- 사전 분포 모델이 잠재 공간 안에서 미래의 잠재 코드 시퀀스를 행동을 조건으로 하여 예측
- 미래의 잠재 코드 시퀀스 생성이 끝나면 VQ-VAE의 디코더가 이 잠재 코드 시퀀스를 실제 비디오 프레임으로 한 번에 변환

이 방식은 픽셀 공간에 의존할 필요 없이 가볍고 효율적인 잠재 공간 안에서 미래를 상상하거나 계획하는 것이 가능하게 한다.
- 그림 7은 모델에 초기 6 프레임을 주고 앞으로 가라, 오른쪽으로 가라는 명령을 주었을 때 그에 맞춰 다음 10 프레임의 비디오를 생성하는 모습을 보임
- 생성된 비디오는 매우 높은 품질을 보임
- 모델이 주어진 행동에 따라 미래를 정확히 예측하고 생성하는 법을 학습했음을 의미
완전성을 기하기 위해 행동 정보 없이 비조건부로 비디오를 생성하는 모델도 학습시켰으며, 비슷한 좋은 결과를 얻었다.
Conclusion
본 논문에서는 VAE를 이산적 잠재 표현을 얻는 벡터 양자화와 결합한 VQ-VAE를 소개했다. VQ-VAE는 기존 이산 VAE의 한계를 극복하고 연속적 VAE와 비견될 만한 성능을 달성했다. 고화질 이미지, 조건부 비디오, 의미 있는 음성 생성 및 화자 변환 등 다양한 태스크에서 압축된 이산 잠재 공간을 통해 장거리 의존성을 성공적으로 모델링함을 보였다. 무엇보다 VQ-VAE는 완전한 비지도 방식으로 원본 오디오로부터 음소와 유사한 고수준 표현을 학습한 최초의 이산 잠재 변수 모델임을 입증했다.
https://proceedings.neurips.cc/paper/2017/hash/7a98af17e63a0ac09ce2e96d03992fbc-Abstract.html
Neural Discrete Representation Learning
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
proceedings.neurips.cc